Project URL in R:
AB-test-notebook-in-R.html
Tools used:
RStudio, Microsoft Excel
Section 1: Project Introduction
Problem Description
We are working on an A/B testing data analysis project, where we analyze data from a website that launched an A/B experiment with the goal of increasing its revenue.
The data provided contains some misleading features that may affect the final outcome of the experiment, and we are tasked with determining if there is a significant difference between the two options.
Business Objective
"The purpose of this project is to analyze the results of an A/B experiment conducted on a website aiming to increase its revenue and provide recommendations based on the findings of the analysis."

Section 2: Data Description
The provided Excel file contains raw data, including user ID, sample type, and revenue generated by the user. The file contains simulated data from an A/B experiment with the following attributes:
| Column | Type of data | Subtype of data | Ranges and categories |
|---|---|---|---|
| 1. User ID | Categorical | Nominal | ID with numbers from 1 to 10000 |
| 2. Variant Name | Categorical | Nominal | Variant, Control |
| 3. Income | Numerical | Continuous | $0 to $196 |
Section 3: Data Cleaning
User Distribution
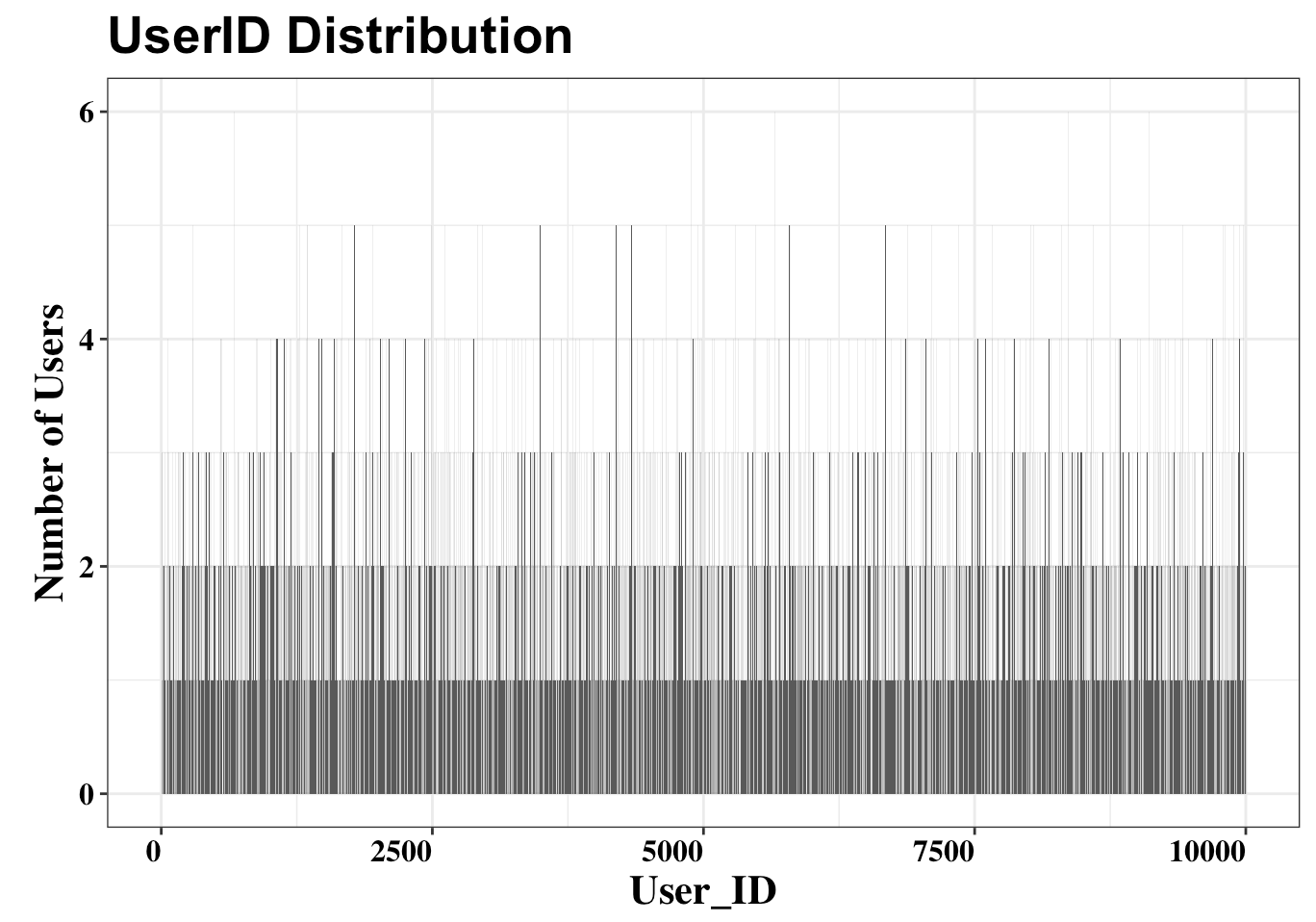
Observations
- Duplicate users: It can be observed that there are a large number of duplicate users, so the cleaning process must be carried out with great care.
User distribution after cleaning
Actions taken for cleaning
- Elimination of users who participated in two experiments: We began by eliminating the biggest possible source of bias, there were users who visited both versions of the website, so these users were completely eliminated.
- Selection of users who repeated an experiment: Finally, there were users who visited the same website multiple times, and it was decided to select the visit that generated the highest income.
Section 4: Exploratory Data Analysis
Income distribution vs variant
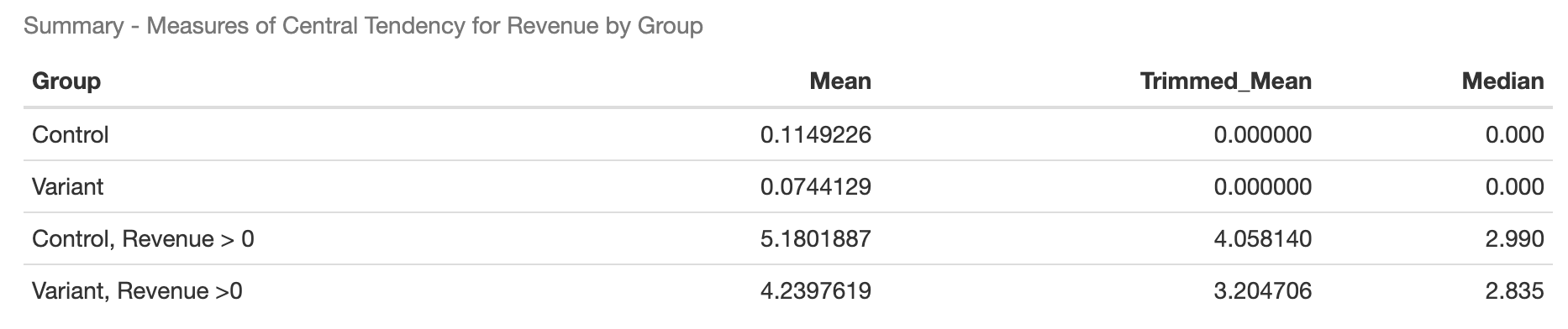
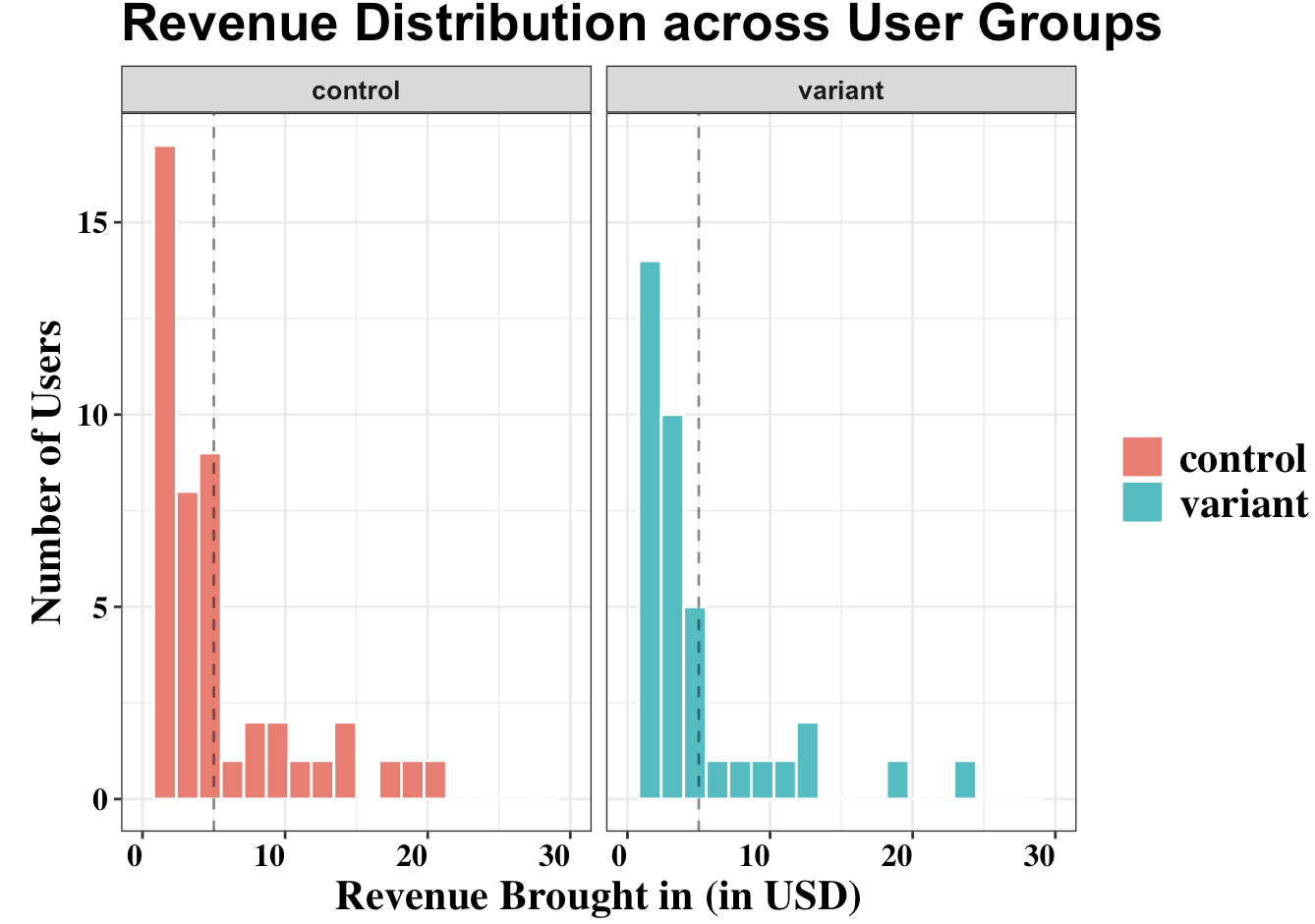
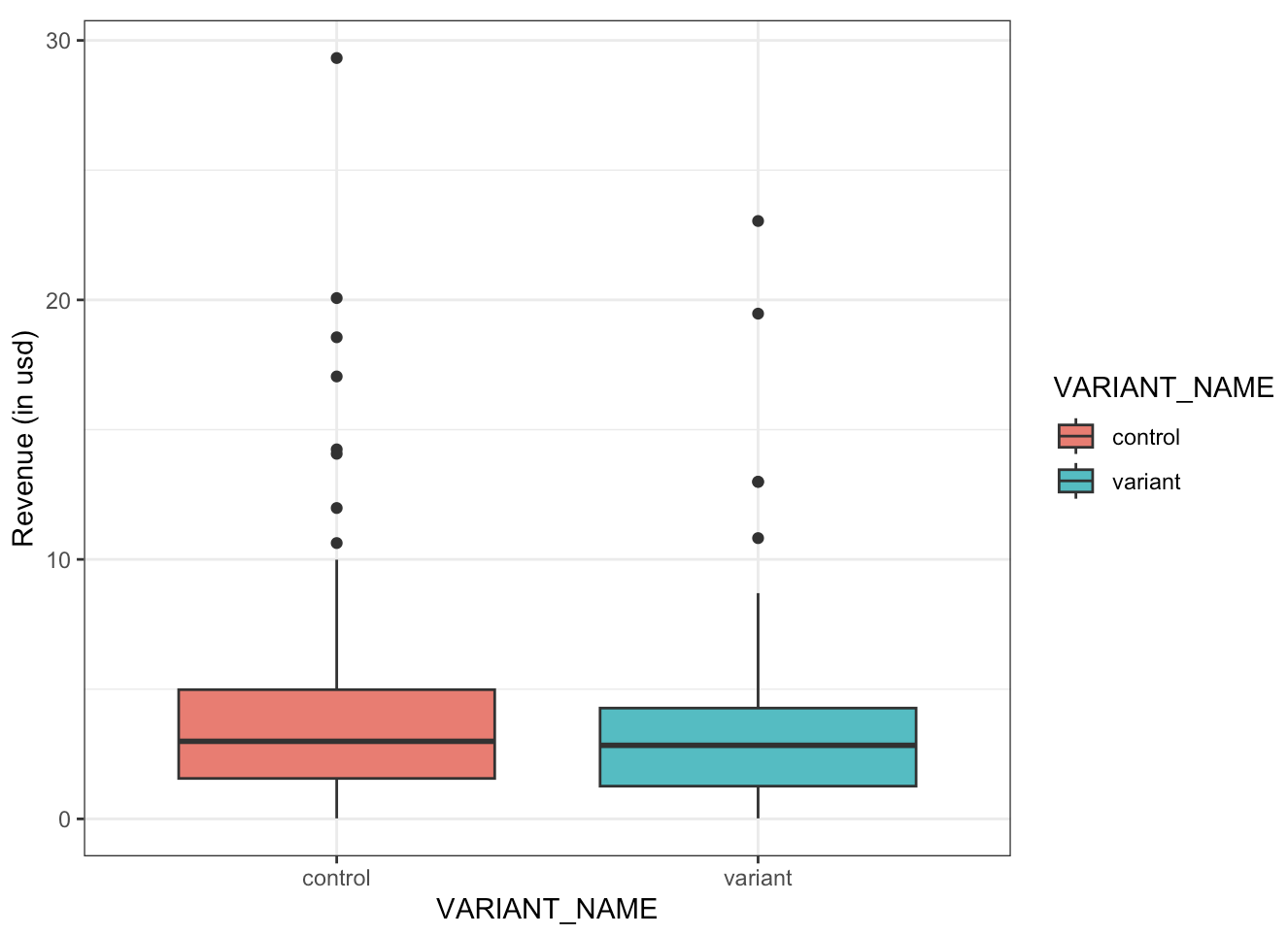
Observations
- Differences in means: A small difference in the means of both variants can be observed, which may be statistically significant.
- Similar distributions: Both variants have very similar distributions, and neither is a normal distribution.
Section 5: Statistical analysis
Standard error and 95% confidence interval for both variants
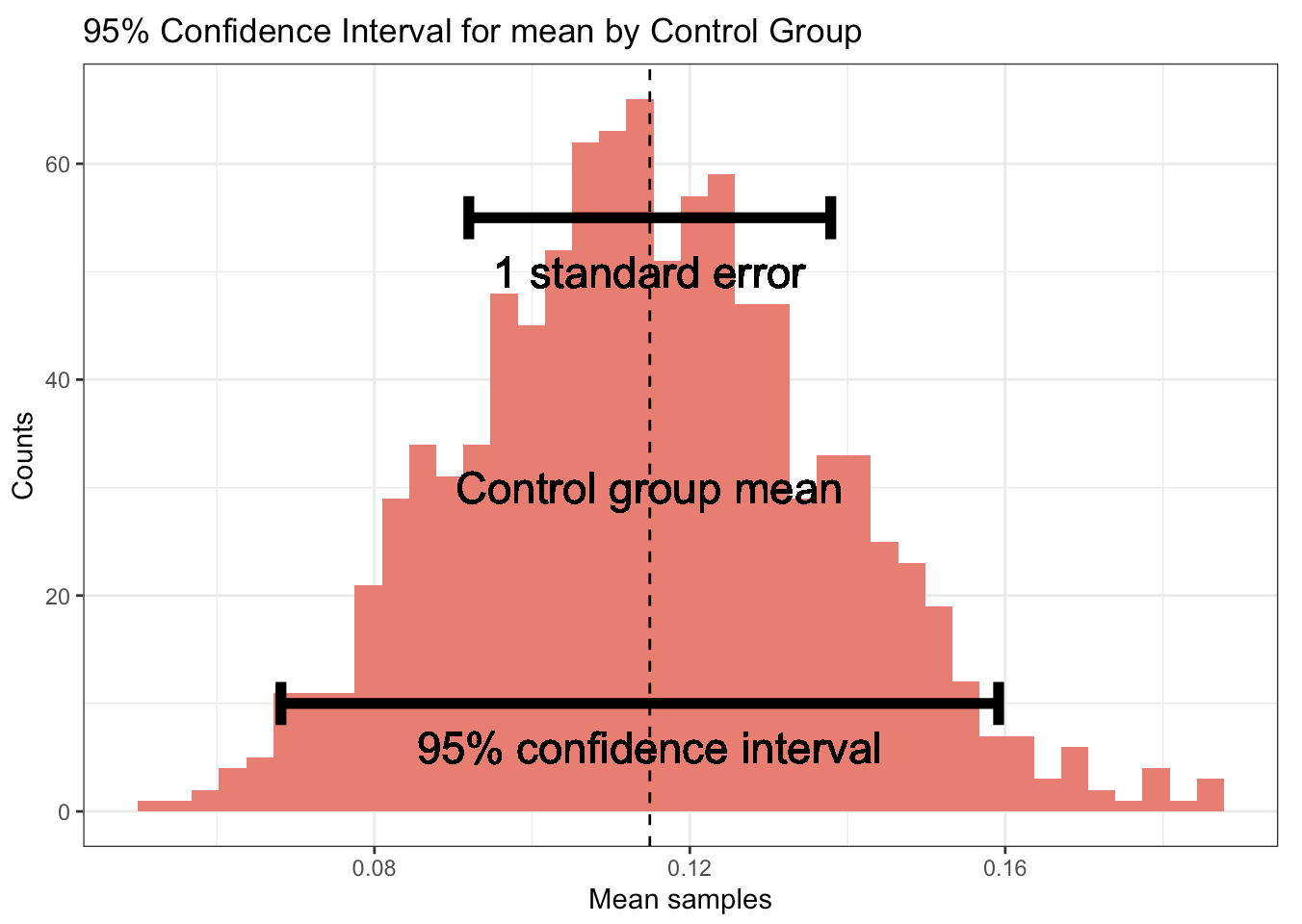
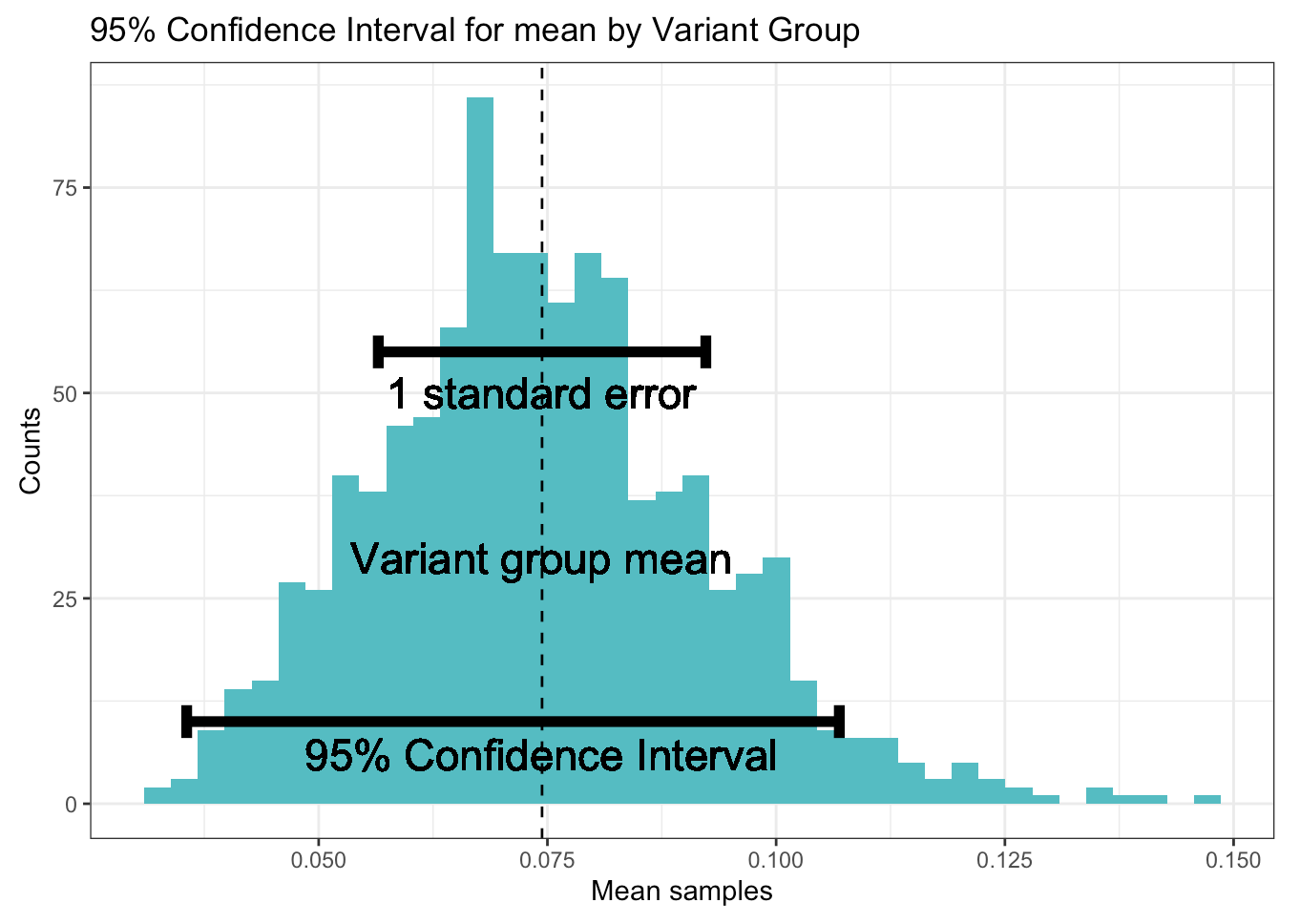
Observations
- Distribution of means: The bootstrap technique was used to obtain the distribution of means for both variants. The distributions overlap due to the proximity of their means.
Density curve for both variants
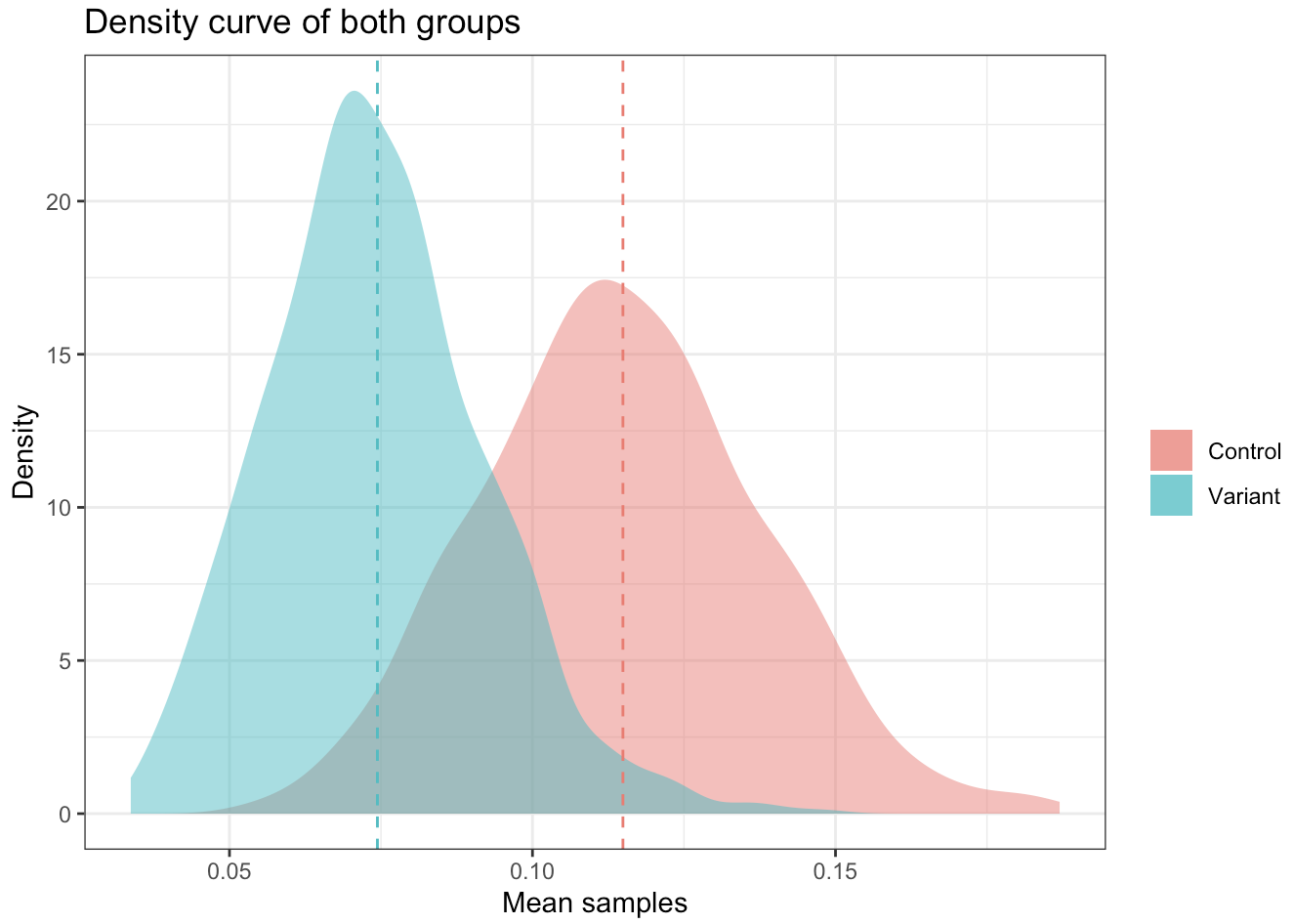
Observations
- Overlapping of both variants: The distribution of means for both variants overlaps, indicating that the difference between them may not be statistically significant.
Is the difference in means statistically significant?
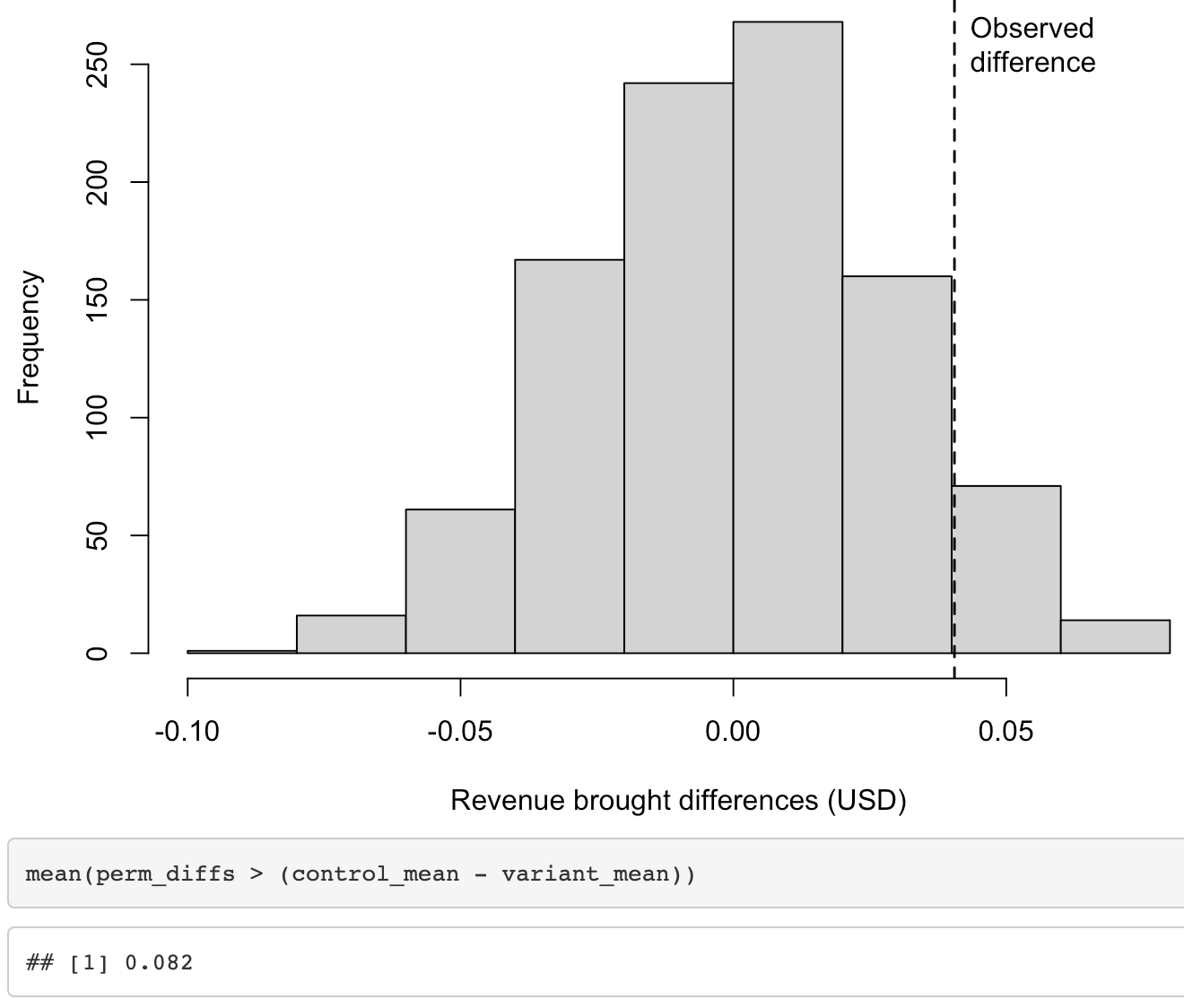
Observations
- Observed difference in means: The permutation technique was used with 1000 iterations to compare the observed difference in means and determine if it was a possible random result.
- alfa >5%: It was observed that 8.2% of the time, the observed result was due to chance. Therefore, it was concluded that this result was not statistically significant, and the null hypothesis was retained.
Section 6: Conclusion
The results suggest that the observed difference in income generated between the control group and the variant group is within the range of variation due to chance, and is therefore not statistically significant.
If resources and interest are available, we recommend continuing the A/B test to collect more data that can lead to more certain results, although we must emphasize that the difference between both tests is not very promising.