
URL del proyecto en R:
Customer_Lifetime_Value_Analysis.notbeook-in-R.html
Herramientas utilizadas:
RStudio, Microsoft Excel, Power Query, Tableau
Sección 1: Introducción al proyecto
Descripción del problema
La retención de clientes es un desafío clave para las empresas, y entender el valor de por vida de los clientes (Customer Lifetime Value, CLV) es crucial para desarrollar estrategias efectivas de retención y crecimiento.
La empresa IBM Watson Analytics desea tomar decisiones informadas sobre la adquisición, retención y desarrollo de los clientes, para optimizar recursos y maximizar la rentabilidad.
Objetivo empresarial
"Crear un modelo predictivo que considere los datos demográficos y de comportamiento de compra proporcionados para estimar el Customer Lifetime Value, y mejorar los programas de retención de clientes."
Sección 2: Descripción de los datos
Features que serán proporcionados para desarrollar el modelo
Para el proyecto se proporcionaron datos históricos en un archivo .csv con 24 columnas y 9134 observaciones. Este archivo cuenta con diversas características demográficas, de comportamiento, información de pólizas y detalles del vehículo de los clientes.
| Columna | Tipo de datos | Sub tipo de datos | Rangos o Categorias |
|---|---|---|---|
| 1. Customer | Categorical | Nominal | ID de 7 caracteres que combina números y letras |
| 2. State | Categorical | Nominal | Arizona, California, Nevada, Oregon, Washington |
| 3. Customer Lifetime Value | Numerical | Continuous | 1,898.00 a 83,325.38 |
| 4. Response | Categorical | Nominal | Yes, No |
| 5. Coverage | Categorical | Ordinal | Basic, Extended, Premium |
| 6. Education | Categorical | Ordinal | Bachelor, College, Doctor, High School or Below, Master |
| 7. Effective to date | Numerical | Discrete | 1/1/2011 a 2/28/2011 |
| 8. Employment Status | Categorical | Nominal | Disabled, Employed, Medical Leave, Retired, Unemployed |
| 9. Gender | Categorical | Nominal | F, M |
| 10. Income | Numerical | Continuous | 0 a 99981 |
| 11. Location code | Categorical | Nominal | Rural, Suburban, Urban |
| 12. Marital Status | Categorical | Nominal | Divorced, Married, Single |
| 13. Monthly Premium Auto | Numerical | Continuous | 61 a 298 |
| 14. Months Since Last Claim | Numerical | Discrete | 0 a 35 |
| 15. Months Since Policy Inception | Numerical | Discrete | 0 a 99 |
| 16. Number of Open Complaints | Numerical | Discrete | 0 a 5 |
| 17. Number of Policies | Numerical | Discrete | 1 a 9 |
| 18. Policy type | Categorical | Nominal | Corporate Auto, Personal Auto, Special Auto |
| 19. Policy | Categorical | Nominal | Corporate L1, Corporate L2, Corporate L3, Personal L1, Personal L2, Personal L3, Special L1, Special L2, Special L3 |
| 20. Renew Offer Type | Categorical | Nominal | Offer1, Offer2, Offer3, Offer4 |
| 21. Sales channel | Categorical | Nominal | Agent, Branch, Call Center, Web |
| 22. Total Claim Amount | Numerical | Continuous | 0.099007 a 2893.239678 |
| 23. Vehicle Class | Categorical | Nominal | Four-Door Car, Luxury Car, Luxury SUV, Sports Car, SUV, Two-Door Car |
| 24. Vehicle Size | Categorical | Ordinal | Large, Medsize, Small |
Sección 3: Descubrimientos - Análisis Exploratorio de Datos
Cobertura vs CLV
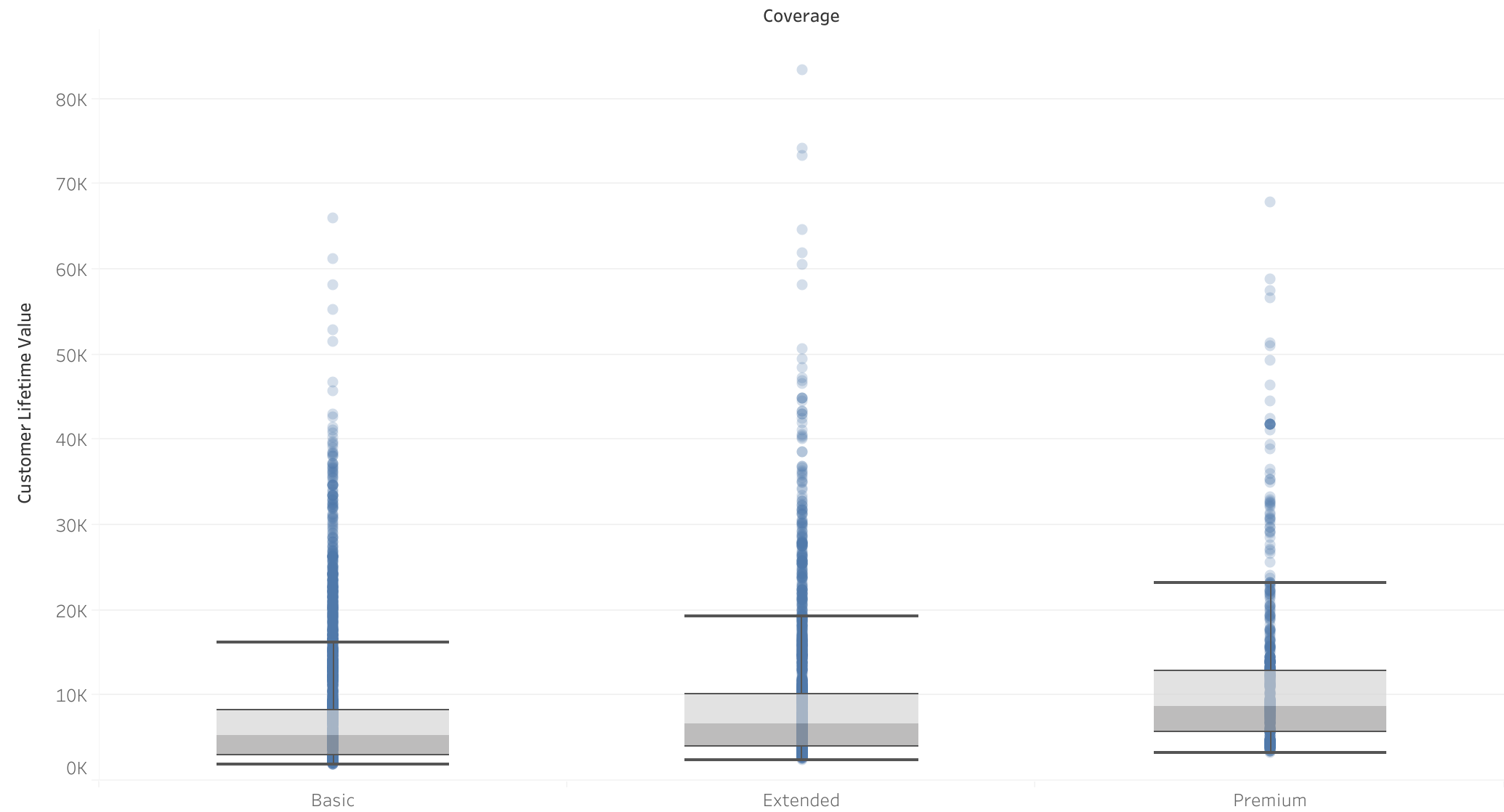
- Correlación entre la cobertura y el CLV: Existe una correlación positiva entre cobertura premium y CLV, como se evidencia en los boxplots.
Clase de vehículo vs CLV
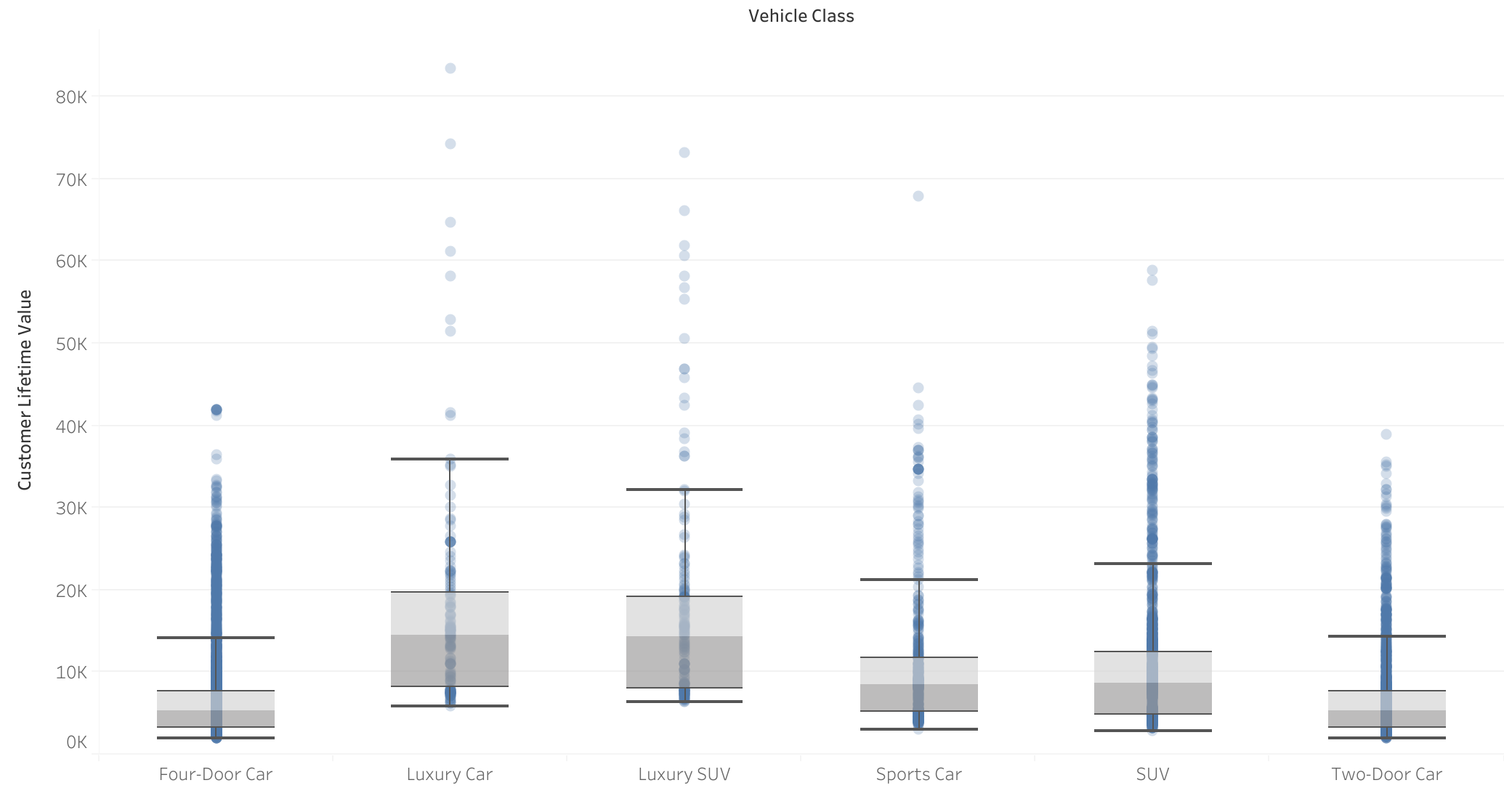
- Correlación entre la clase de vehículo y el CLV: Los clientes con vehículos de lujo presentan un mayor CLV, lo que indica que la clase del vehículo influye en el CLV.
Pago Mensual del Seguro vs CLV
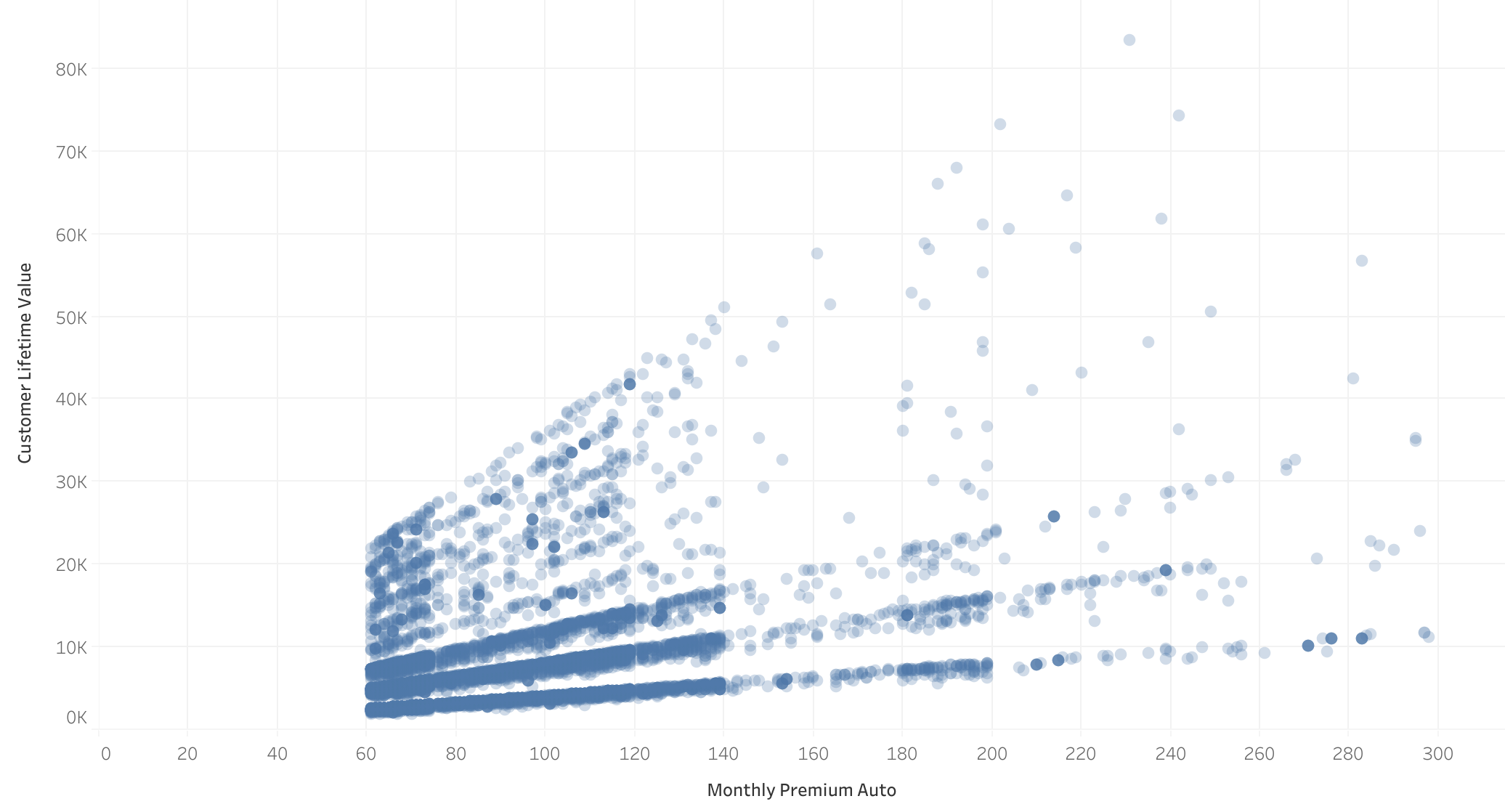
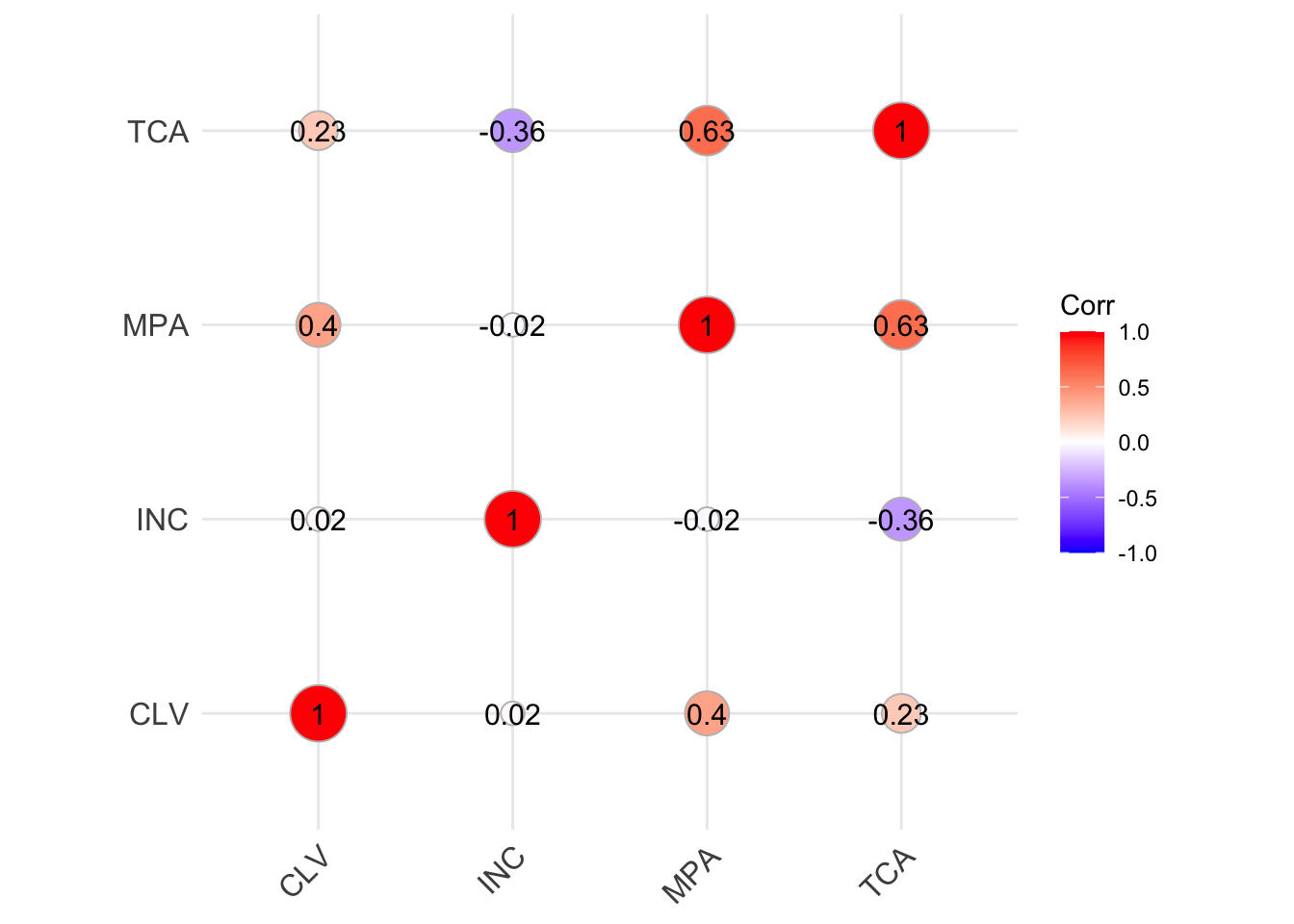
- La mayor correlación con CLV: la matriz de correlación muestra que el pago mensual del seguro tiene la mayor correlación numérica con el CLV.
- Tendencia clara en el scatterplot: Se aprecia que cuanto más paga un cliente mensualmente, mayor es su CLV.
Total reclamado vs CLV
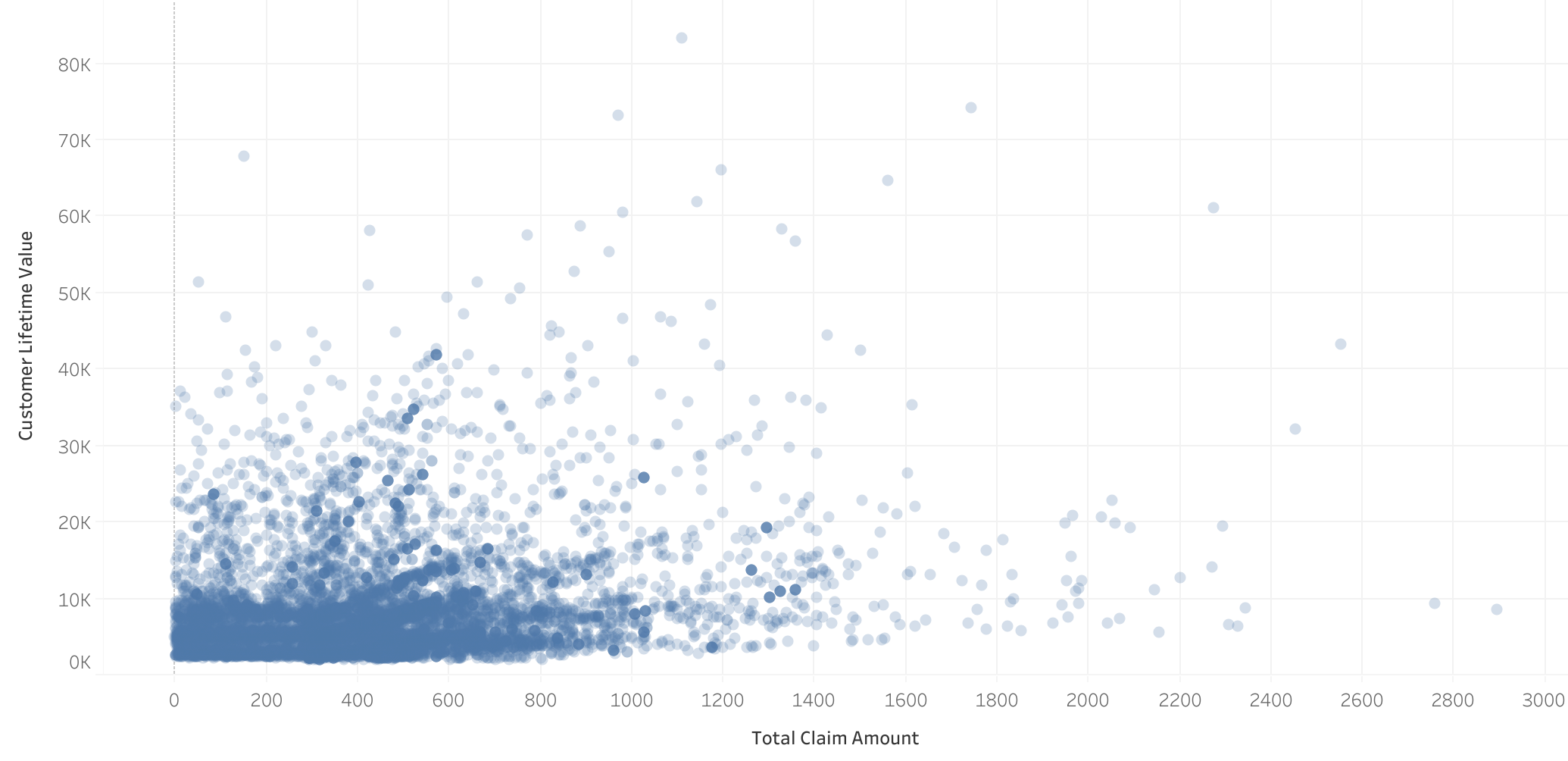
- Correlación entre total reclamado y CLV: Aunque no es tan evidente en el scatterplot, existe correlación entre el total reclamado y CLV, corroborado por el modelo de regresión lineal simple.
Número de seguros vs CLV
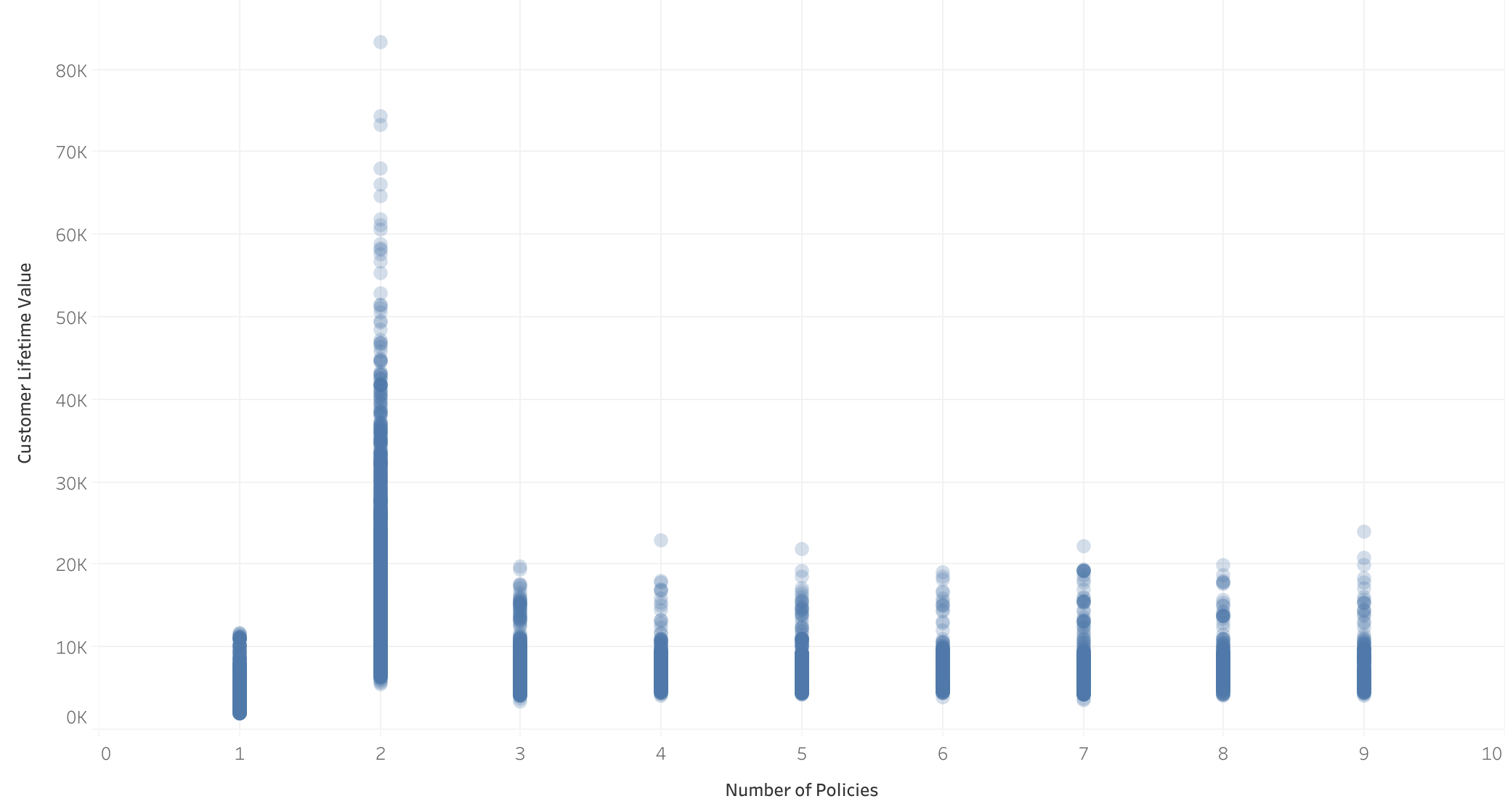
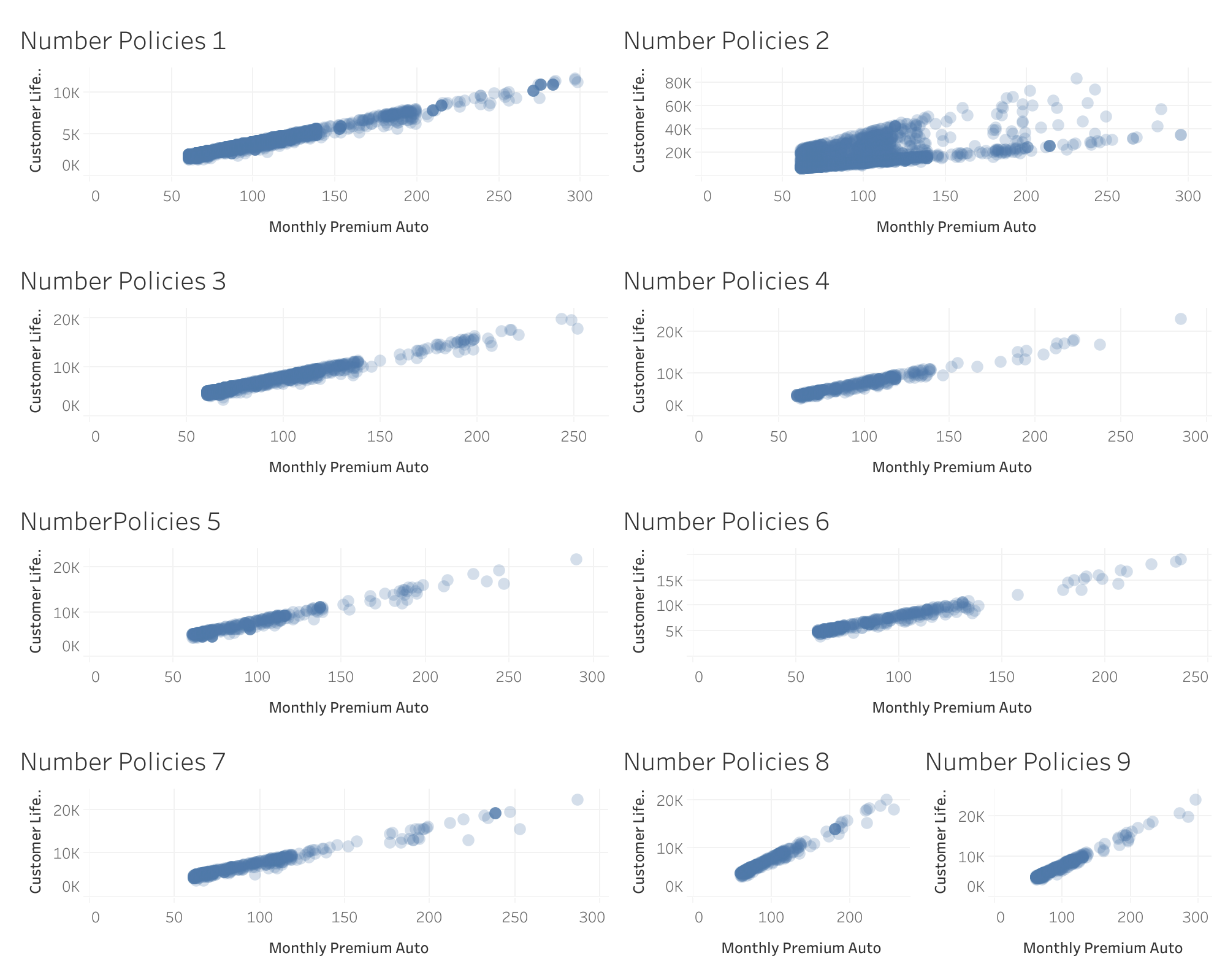
- Aumento atípico del CLV para clientes con 2 seguros: Se observa un incremento inusual en el CLV de estos clientes.
- Pérdida de linealidad para clientes con 2 seguros: El comportamiento de los clientes sin 2 seguros es lineal.
Sección 4: Construcción del modelo con Regresión lineal
Regresión lineal multiple
División de datos en conjuntos de entrenamiento y validación
Se optó por una división 80%/20%.
Multicolinealidad
Se detectó multicolinealidad en un término (VIF > 5.0).
Regresión Stepwise
Este método se utilizó para seleccionar variables con mayor efecto y eliminar la multicolinealidad.

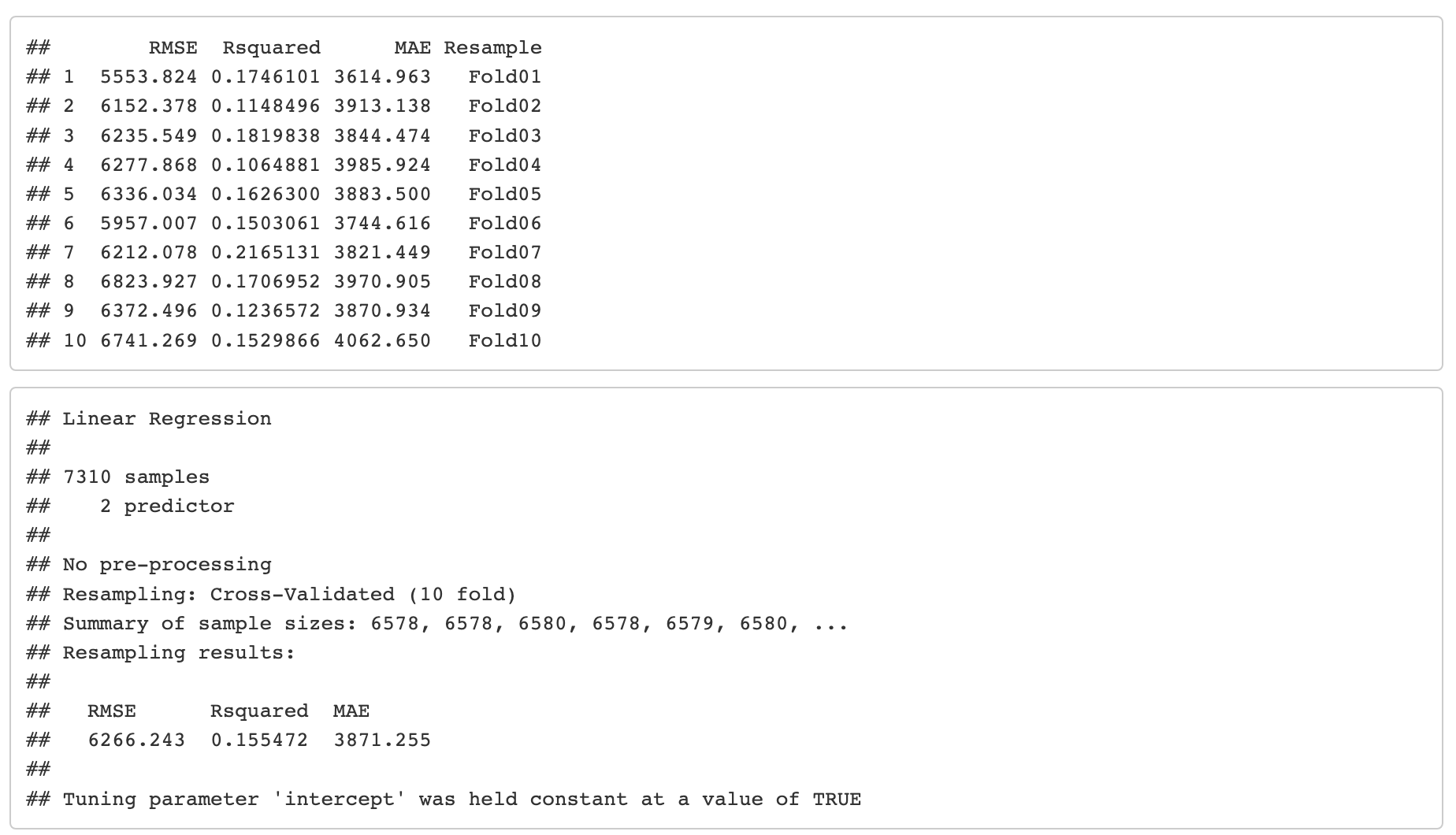
Resultados de validación cruzada 10 fold
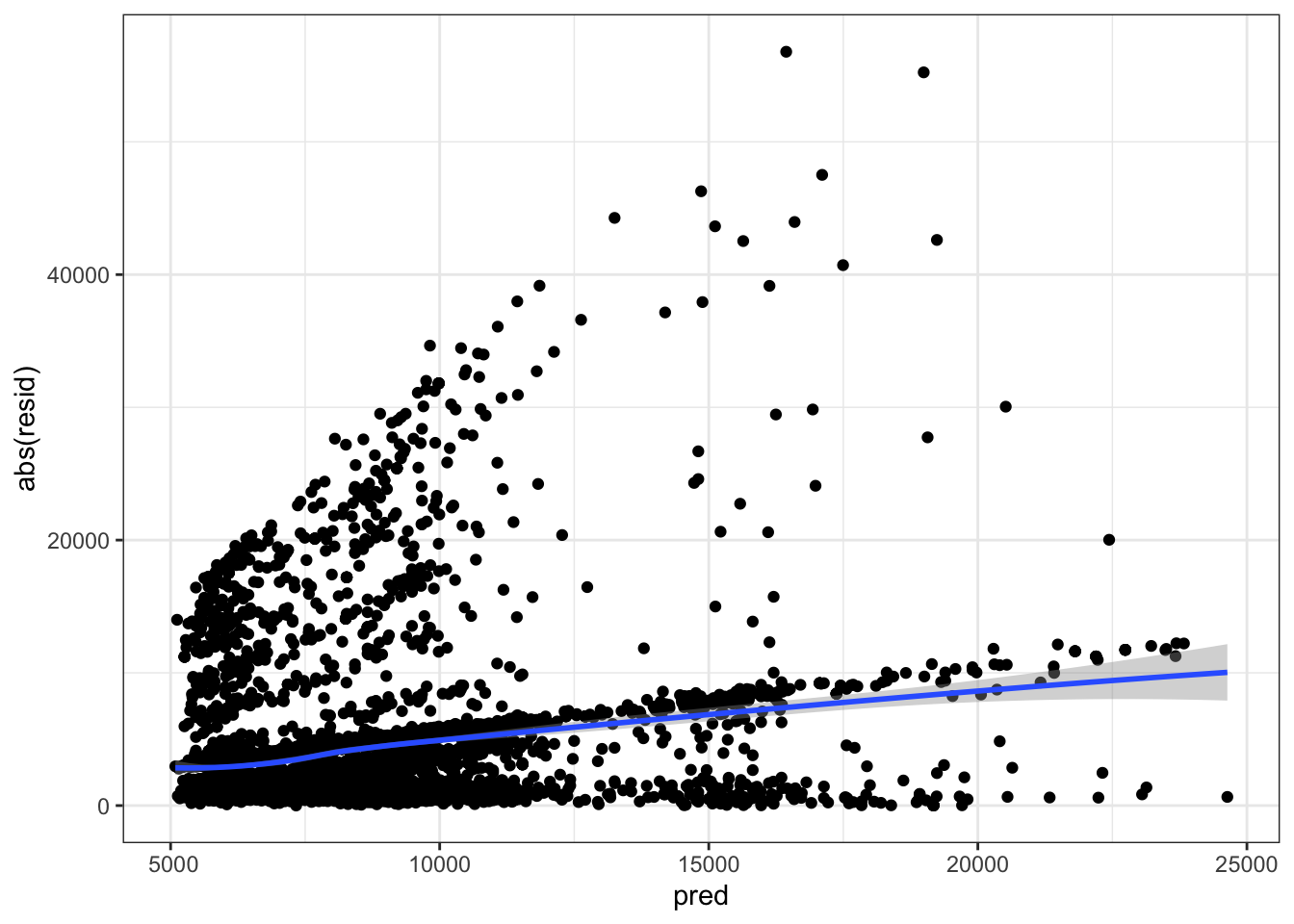
Valor absoluto de los residuos VS valor predecido
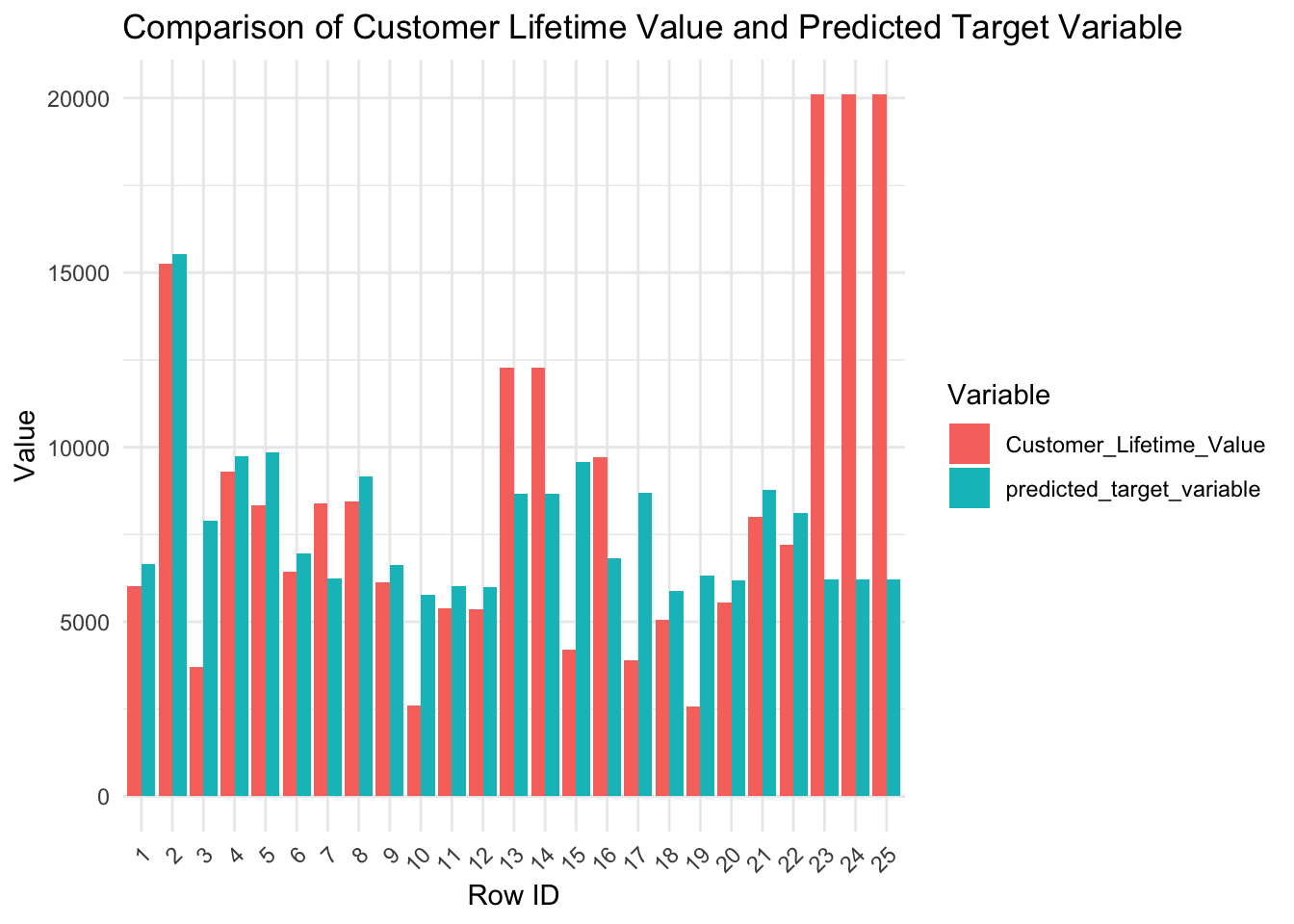
Desempeño fuera de muestra

Section 5: Mejorando el modelo con KNN
K Nearest Neighbor.
Anteriormente, descubrimos que solo cuando el número de pólizas es 2, la relación entre el Valor de por Vida del Cliente (valor objetivo) y la Prima Mensual del Auto (una característica) varía enormemente. Sospechamos que el modelo podría mejorar su precisión utilizando un algoritmo que pueda captar esta relación no lineal.
Rendimiento fuera de la muestra

Visualizando los valores observados vs. los valores predichos en la muestra de retención
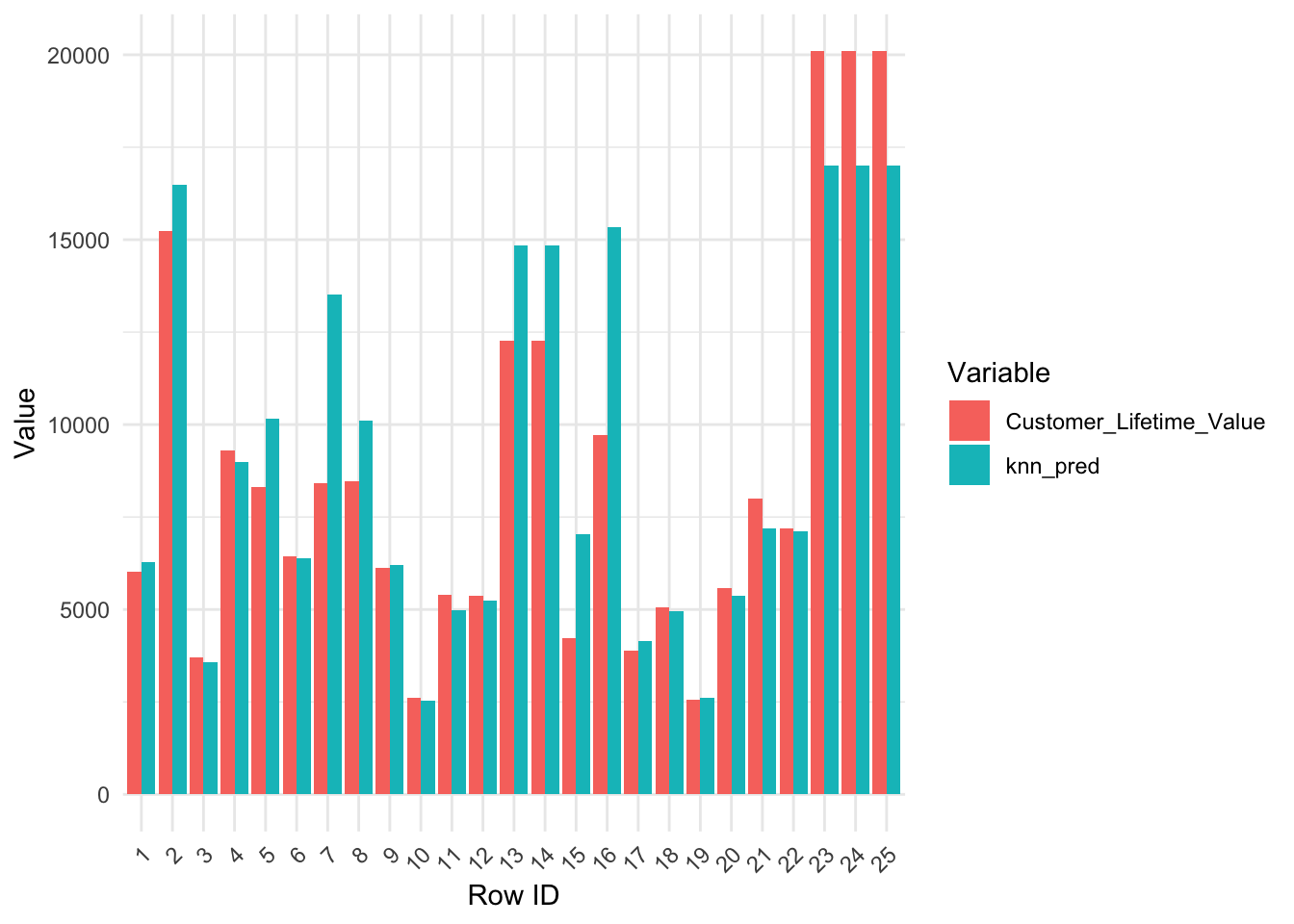
Estableciendo KNN como característica del modelo
Ahora intentemos establecer KNN como una característica y usarlo en el modelo de regresión lineal múltiple para ver si eso podría mejorar aún más el modelo.Validación cruzada 10 fold
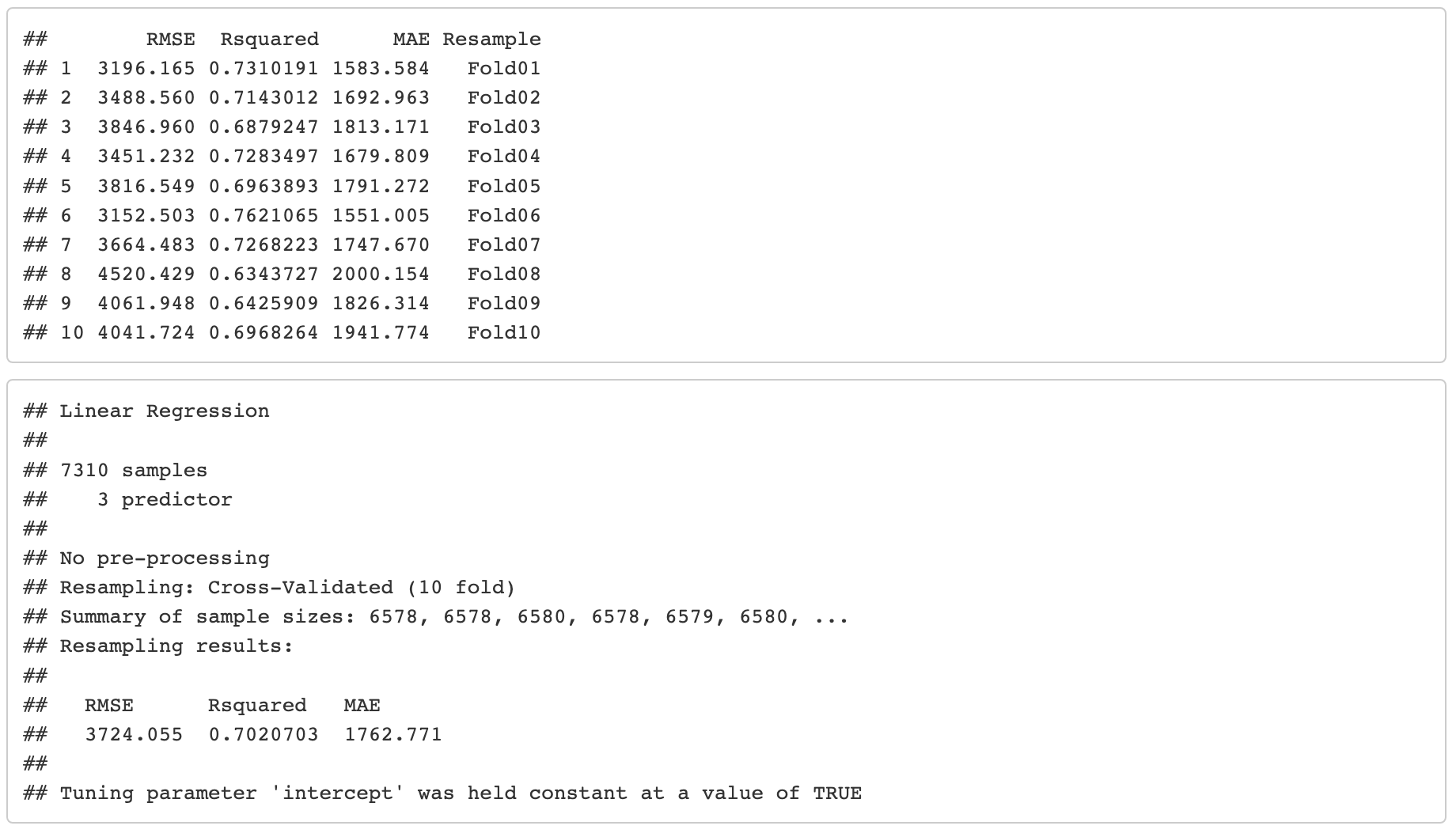
Evaluando el modelo en nuevos datos (fuera de muestra)

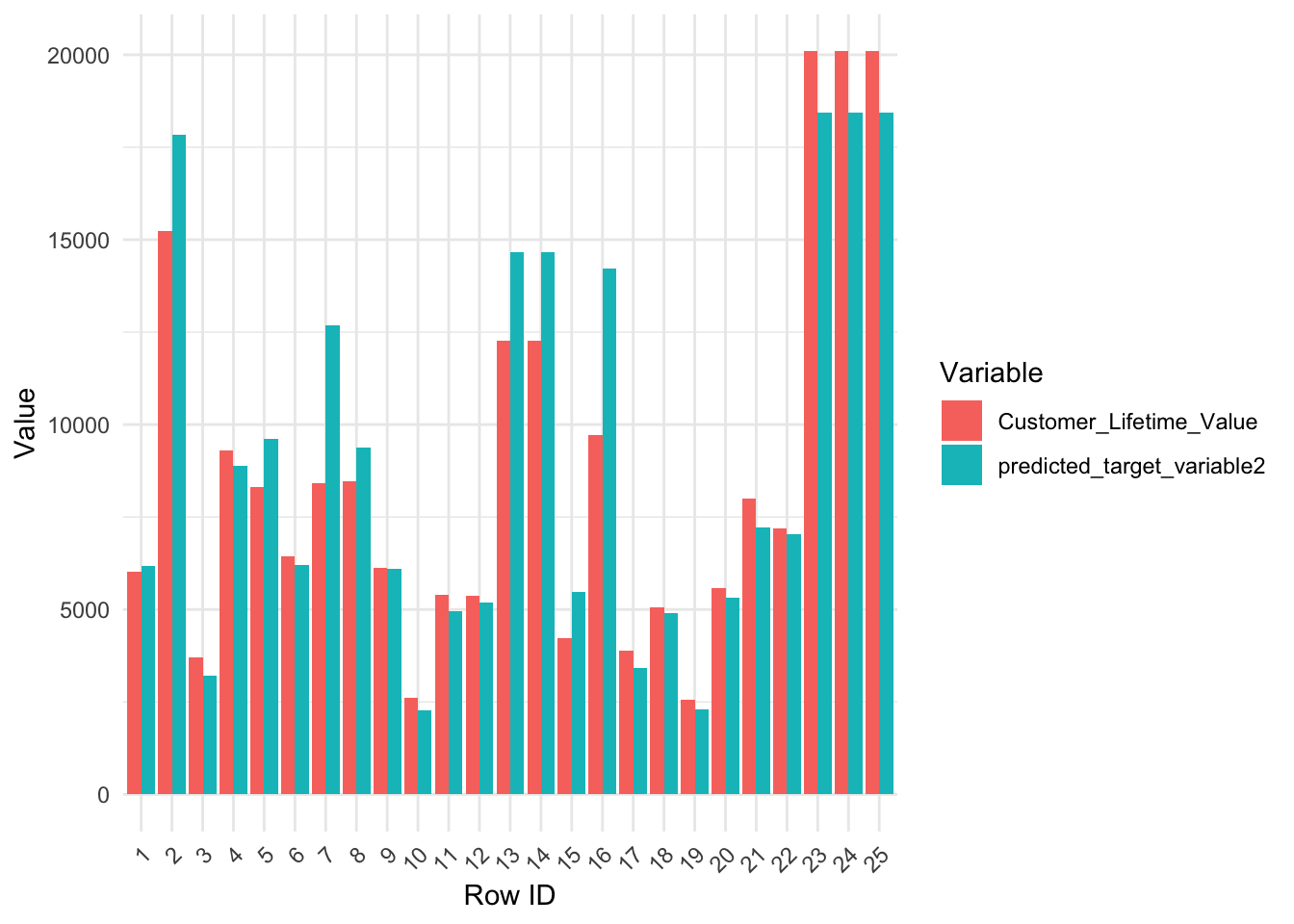
Visualizando los valores observados vs. los valores predecidos fuera de muestra
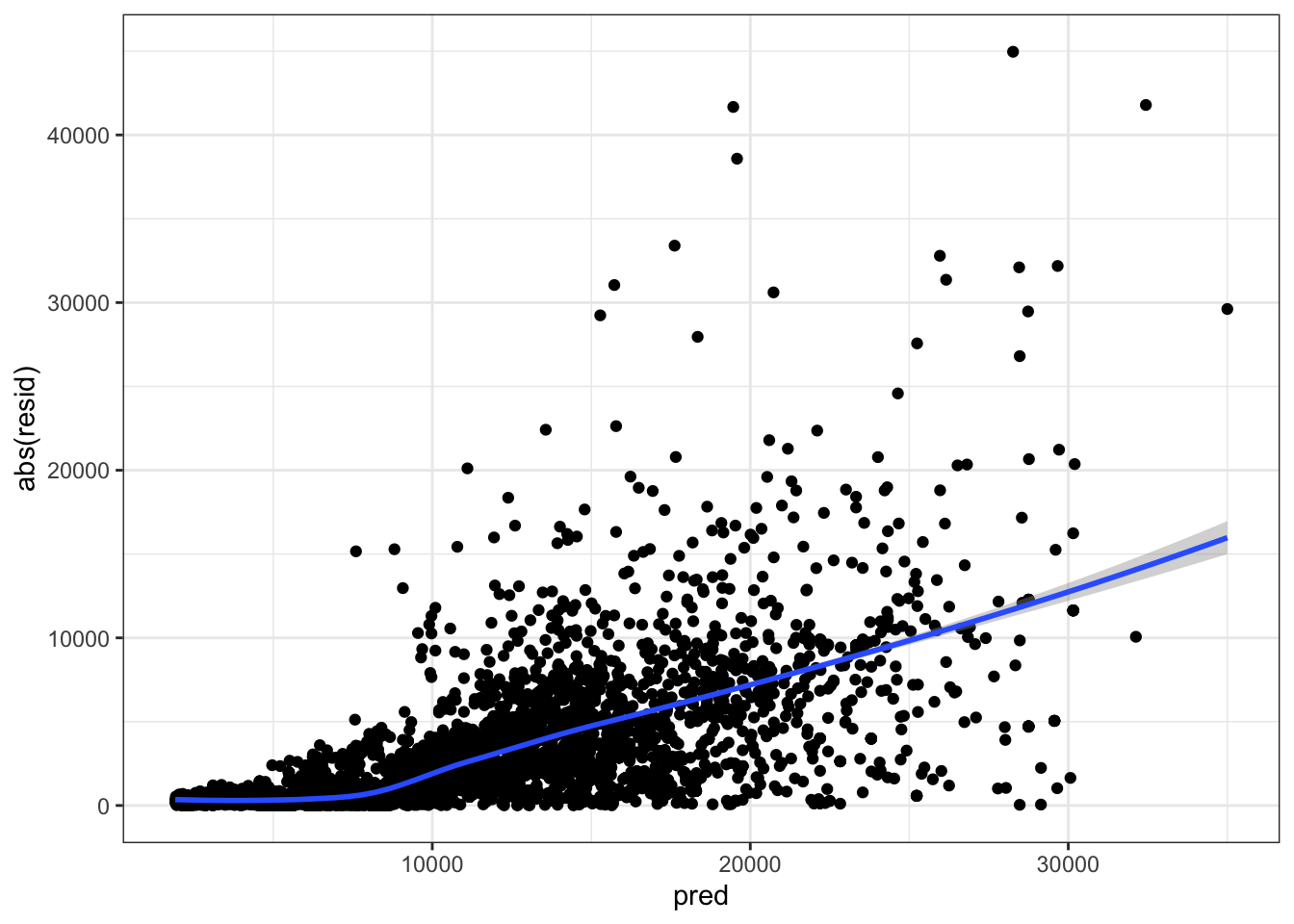
Visualizando el valor absoluto de los residuos frente a los valores predichos
Sección 6: Conclusión
Nuestro modelo inicial de regresión lineal arrojó un RMSE fuera de la muestra de 6433.889 y un R^2 de 0.1738. Aunque la precisión del modelo era limitada, las conclusiones derivadas de los coeficientes aún pueden utilizarse para informar decisiones empresariales encaminadas a aumentar el CLV.
El segundo modelo mejoró significativamente el primero mediante la adopción de un enfoque de conjunto, que incorporó el resultado de los K Vecinos más Cercanos (KNN) como una característica adicional. El modelo final logró un RMSE de 3994.279 y un R^2 de 0.6813.
La mejora sustancial en el rendimiento de nuestro modelo se atribuye a la detección de un patrón inusual entre los clientes que tienen dos pólizas, que nuestro modelo original de regresión lineal no logró capturar. Se recomienda investigar más a fondo este comportamiento para identificar la causa subyacente, lo que podría llevar al desarrollo de un modelo más preciso para predecir el CLV.