
URL del proyecto en R:
Clasification-model.notbeook-in-R.html
Herramientas utilizadas:
RStudio, Microsoft Excel, Power Query, Tableau
Sección 1: Introducción al proyecto
Descripción del problema
IFood, una empresa de delivery de comida a través de una aplicación. Ifood enfrenta un estancamiento en el crecimiento y busca optimizar el rendimiento de sus actividades de marketing en las cuales no se está haciendo un buen trabajo del manejo del presupuesto.
A pesar de tener sólidos ingresos en los últimos tres años, las perspectivas de crecimiento no son prometedoras. Por lo tanto, la compañía desea abordar este problema centrándose en mejorar la eficiencia de sus campañas de marketing, particularmente en la próxima campaña que tiene como objetivo vender un nuevo dispositivo a su base de clientes existente.
Objetivo empresarial
"Elaborar un modelo predictivo basado en datos históricos de los clientes que identifique aquellos con mayor probabilidad de responder positivamente a la próxima campaña de marketing."
Este modelo debe permitir al departamento de marketing tomar decisiones cuantitativas e informadas, lo que resultará en un mejor uso del presupuesto anual y, en última instancia, en un aumento en las ventas y el crecimiento de la empresa.
Sección 2: Descripción de los datos
Features que serán proporcionados para desarrollar el modelo
Para el proyecto se proporcionó un conjunto de datos que consta registros de 2206 clientes de la empresa XYZ con información sobre:
- Perfiles de clientes
- Preferencias de productos
- Éxitos/fracasos de las campañas
- Rendimiento de los canales de comunicación
| Columna | Tipo de datos | Sub tipo de datos | Rangos o Categorias |
|---|---|---|---|
| 1. ID | Categorical | Nominal | 0-11,191 |
| 2. Age | Numerical | Discrete | 18-21 |
| 3. Income | Numerical | Continuous | 1,730-666,666 |
| 4. Kidhome | Numerical | Discrete | 0-2 |
| 5. Teenhome | Numerical | Discrete | 0-2 |
| 6. Dt_Customer | Numerical | Discrete | 2012-07-30 to 2014-06-29 |
| 7. Recency | Numerical | Discrete | 0-99 |
| 8. MntWines | Numerical | Continuous | 0-1,493 |
| 9. MntFruits | Numerical | Continuous | 0-199 |
| 10. MntMeatProducts | Numerical | Continuous | 0 a 1725 |
| 11. MntFishProducts | Numerical | Continuous | 0-259 |
| 12. MntSweetProducts | Numerical | Continuous | 0-263 |
| 13. MntGoldProds | Numerical | Continuous | 0-362 |
| 14. NumDealsPurchases | Numerical | Discrete | 0 a 15 |
| 15. NumWebPurchases | Numerical | Discrete | 0 a 27 |
| 16. NumCatalogPurchases | Numerical | Discrete | 0 a 28 |
| 17. NumStorePurchases | Numerical | Discrete | 0-13 |
| 18. NumWebVisitsMonth | Numerical | Discrete | 0-20 |
| 19. AcceptedCpm1 | Categorical | Nominal | 0-1 |
| 20. AcceptedCpm2 | Categorical | Nominal | 0-1 |
| 21. AcceptedCpm3 | Categorical | Nominal | 0-1 |
| 22. AcceptedCpm4 | Categorical | Nominal | 0-1 |
| 23. AcceptedCpm5 | Categorical | Nominal | 0-1 |
| 24. Complain | Categorical | Nominal | 0-1 |
| 25. Response | Categorical | Nominal | 0-1 |
| 26. Education | Categorical | Nominal | Graduation, Master, PhD, 2nd Cycle, Basic |
| 27. Marital Status | Categorical | Nominal | Married, Single, Widow, Divorced, Together, Alone, YOLO, Absurd |
Sección 3: Descubrimientos - Análisis Exploratorio de Datos
Educación vs Respuesta
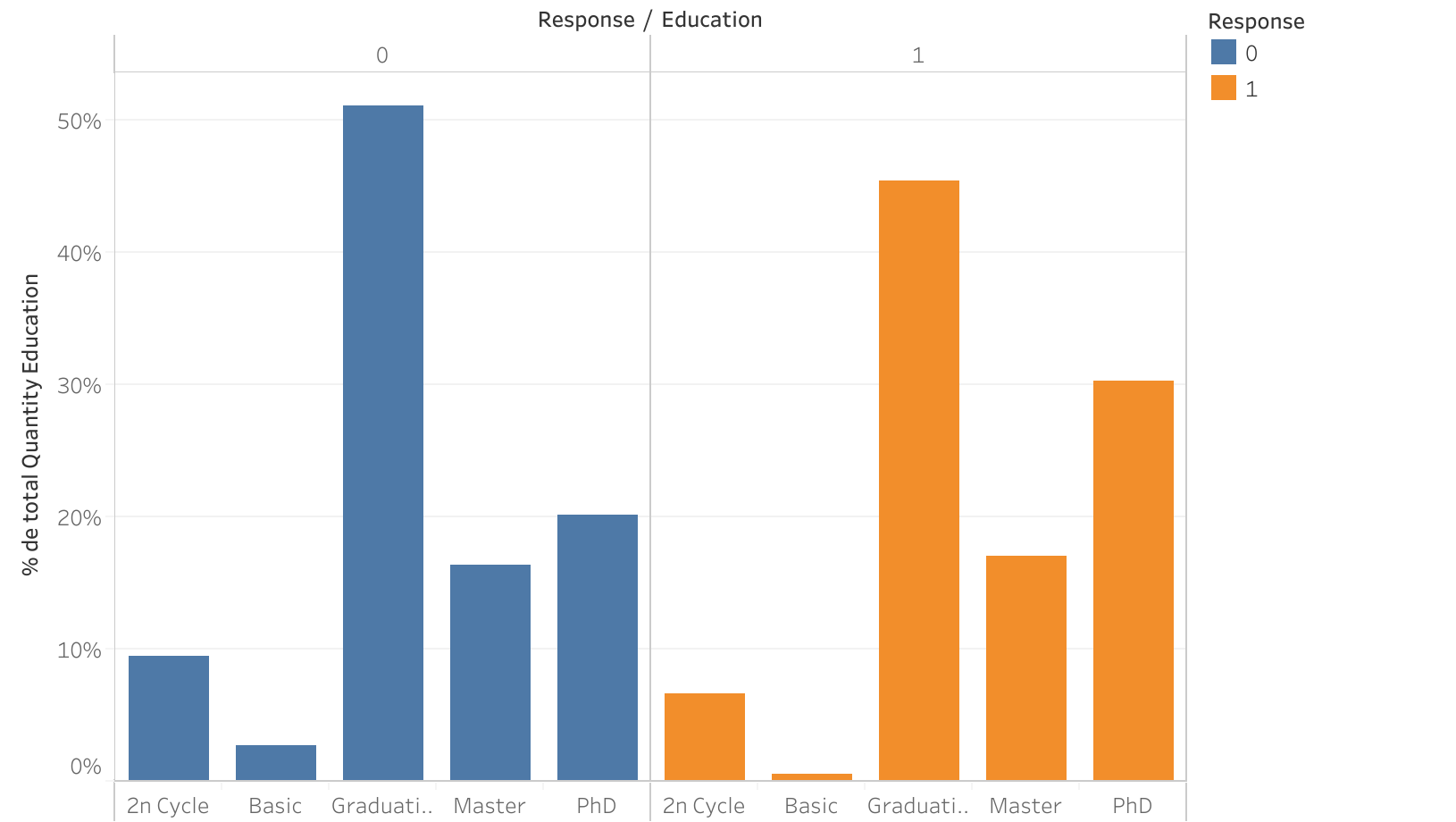
- Los PhD mostraron una mayor probabilidad de responder positivamente a la campaña: De los perfiles educativos, el que tuvo una diferencia más notoria (casi del 10%) fue el del PhD que respondió más positivamente a la campaña.
Respuesta a campañas anteriores vs Respuesta a campaña actual
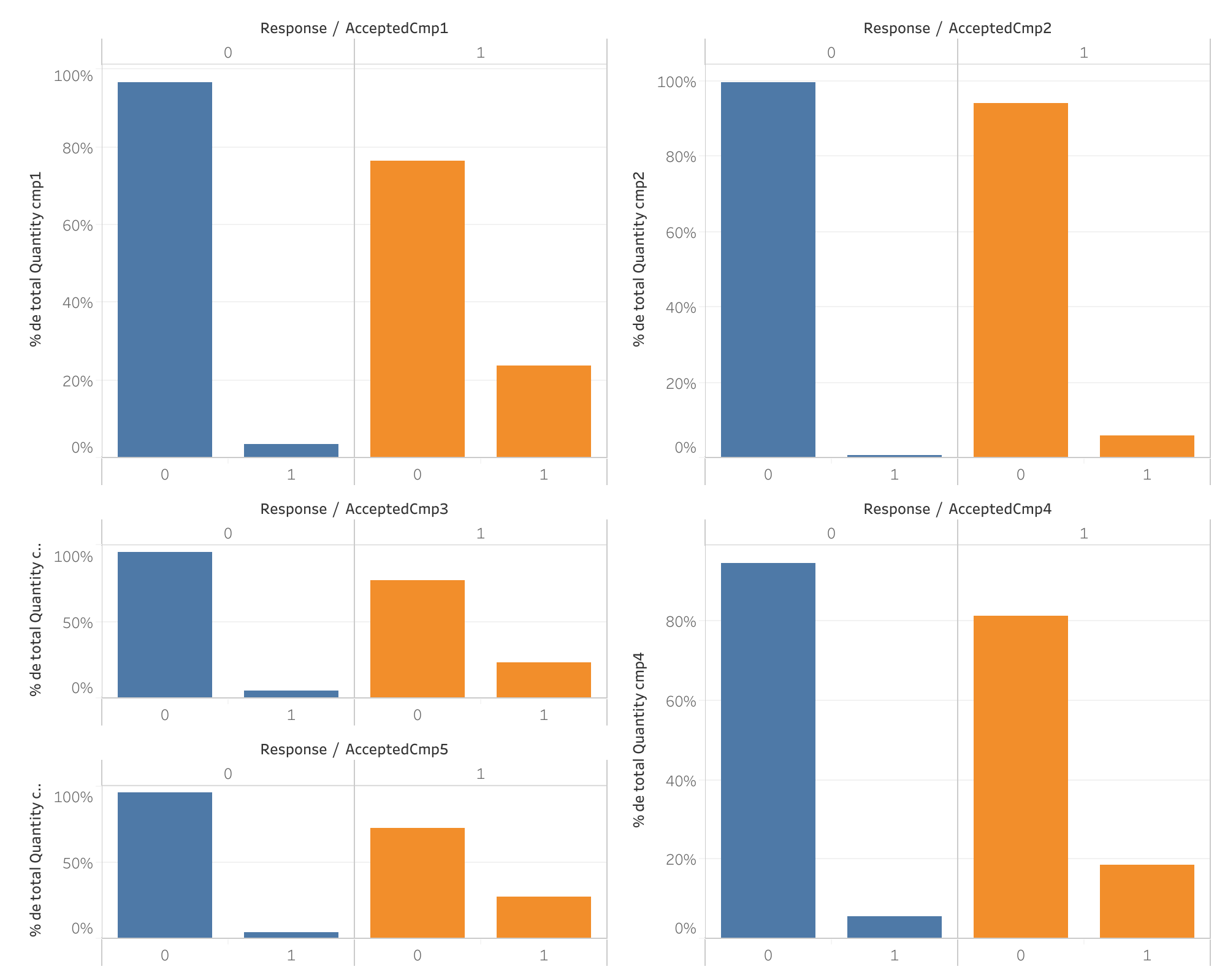
- El pasado se repite: Clientes que respondieron positivamente a campañas previas mostraron una mayor probabilidad de responder positivamente a la campaña actual.
Meses de antiguedad vs Respuesta a campaña actual
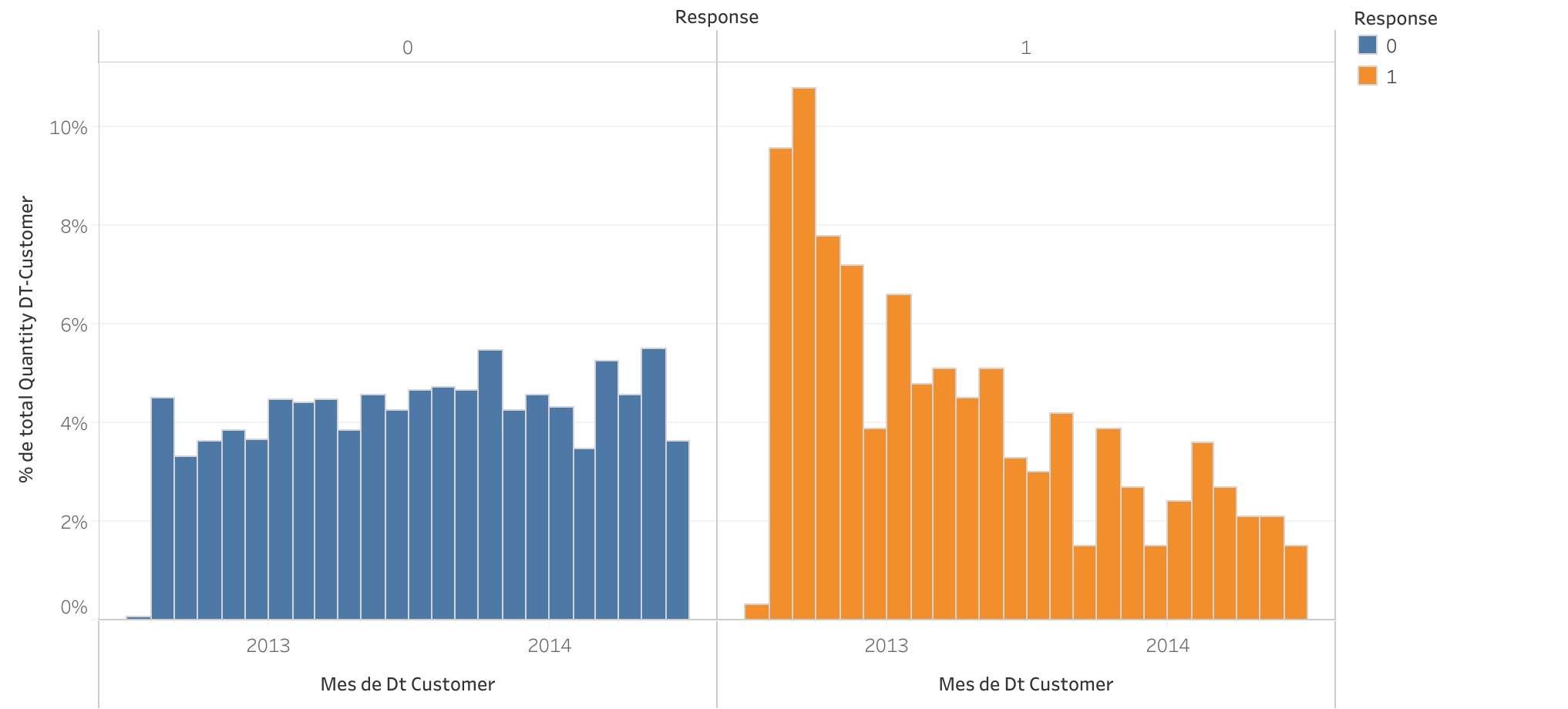
- Mayor antiguedad, mejor respuesta: Los clientes con mayor antigüedad desde su primer uso de nuestros servicios muestran una mayor probabilidad de responder positivamente a la campaña actual.
Gasto mensual vs Respuesta a campaña actual
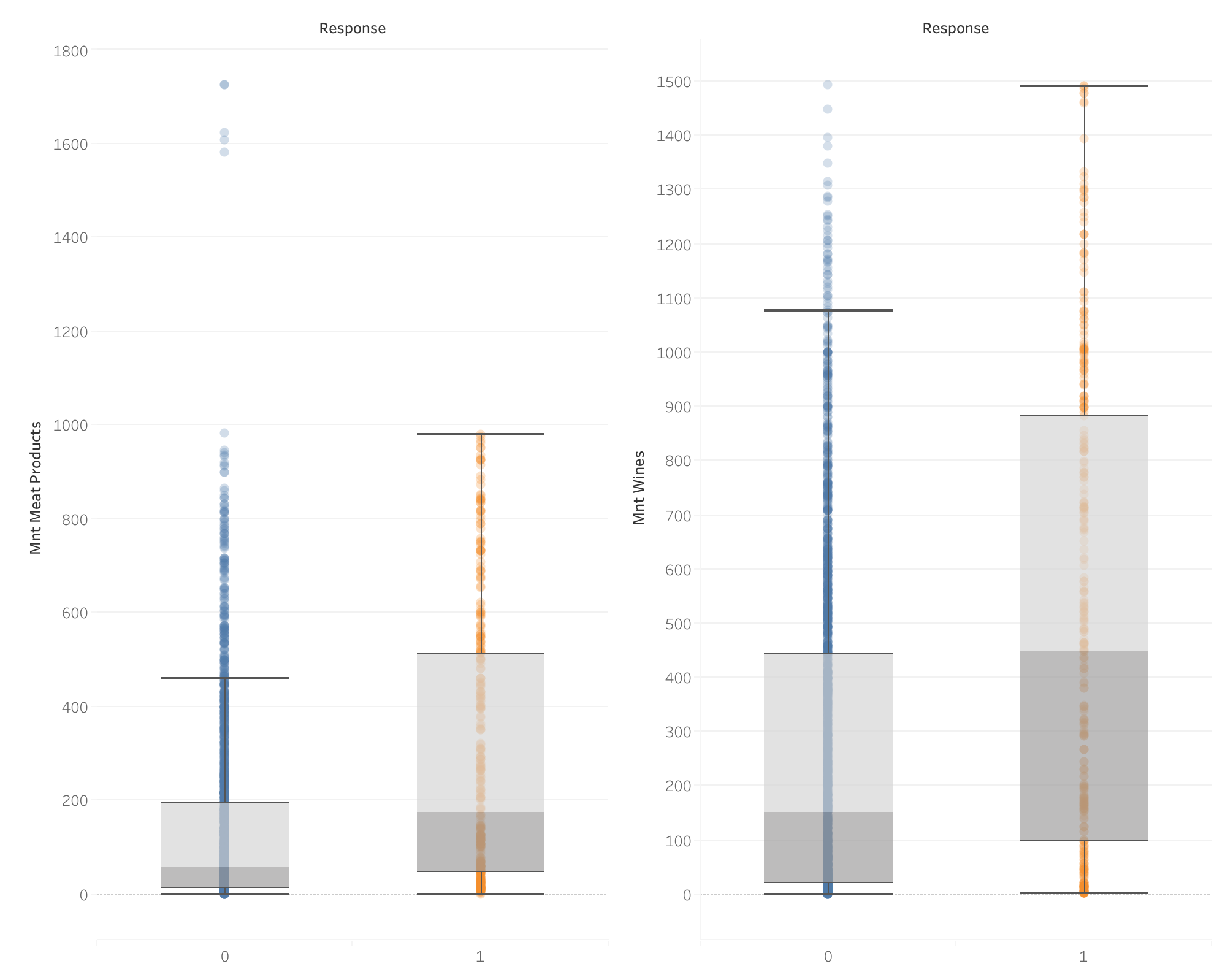
- Los que más gastan tienen una mejor respuesta: Los clientes que gastan más, particularmente en estás dos categorias (vinos y carnes), muestran una mayor probabilidad de responder positivamente a la campaña actual.
Otros atributos vs Respuesta a campaña actual
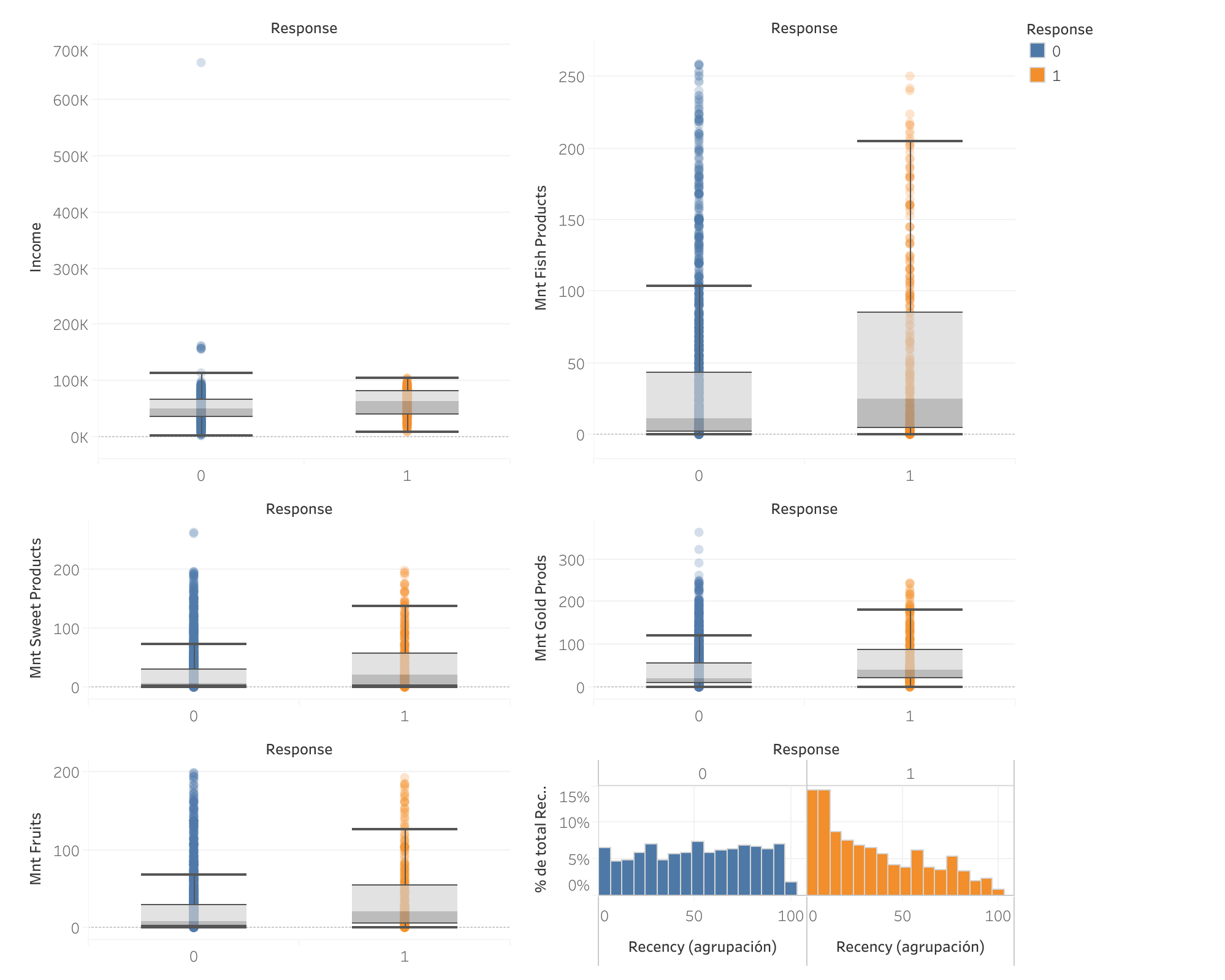
- Diferencias interesantes: Se identificaron diferencias notables en varios atributos, pero ninguna de ellas resultó estadísticamente significativa ni tuvo un impacto considerable en la capacidad predictiva del modelo. Por lo tanto, estos atributos no se tomaron en cuenta al desarrollar el modelo.
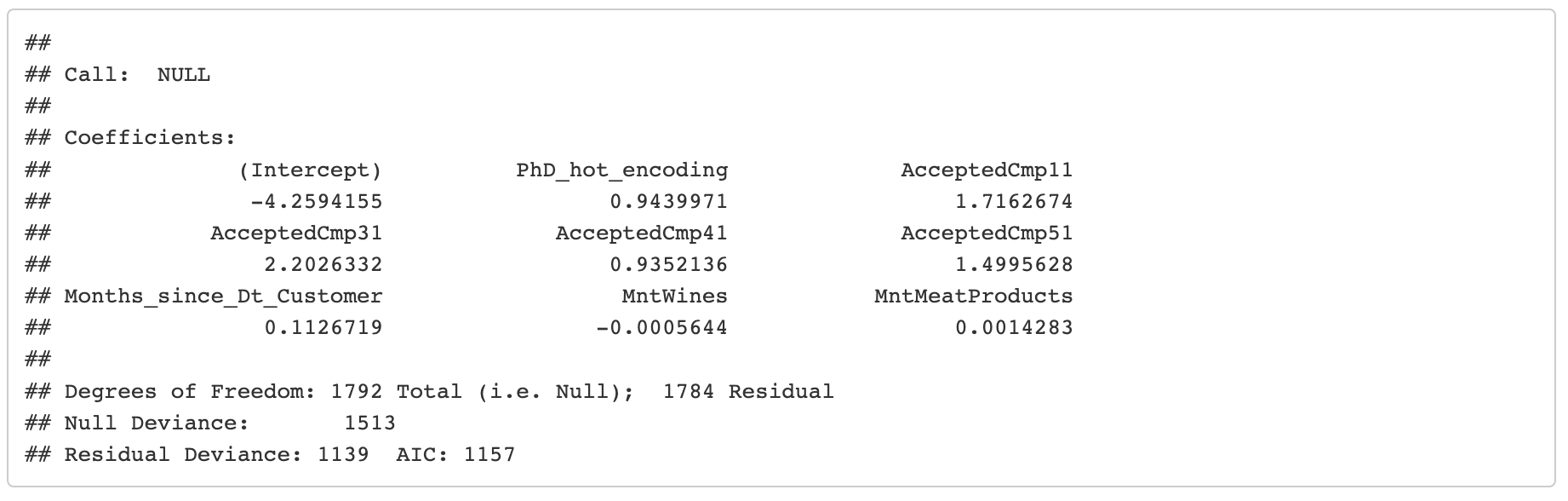
Sección 4: Construcción del modelo con Regresión Logística
Esta sección inicia luego de las pruebas estadísticas y análisis del efecto de los atributos, por lo cuál ya se han seleccionado cuáles atributos utilizará el modelo. Si quieres saber más a detalle todo el proceso visita el URL del proyecto que está al inicio de esta página web.
Regresión logística
División de datos en conjuntos de entrenamiento y validación
Se optó por una división 80%/20%.
Multicolinealidad
No se detectó multicolinealidad en ningun término (VIF menor a 5.0).
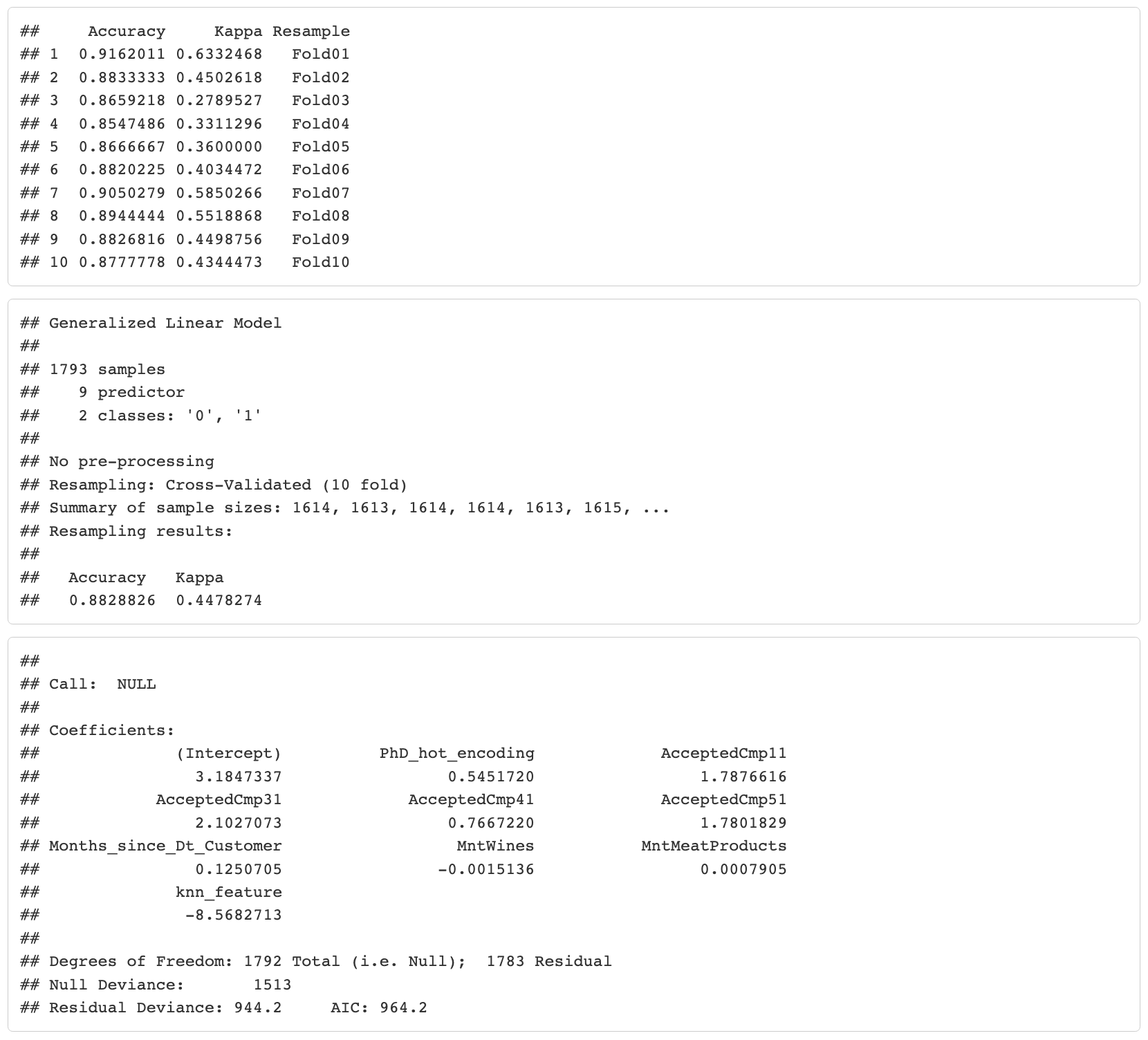
Resultados de validación cruzada 10 fold
Se observa un alto accuracy del modelo (arriba del 85%).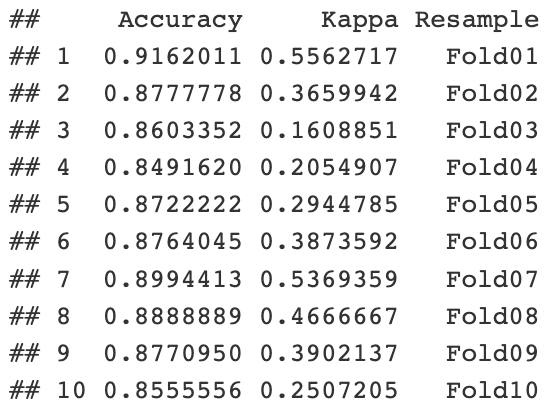

Evaluación de precision, recall y specificity del modelo
El modelo es bueno identificando positivos verdaderos (71% precision) pero le falta sensitividad (30% recall), aunque la sensitividad podría no ser tan importante para este proyecto.

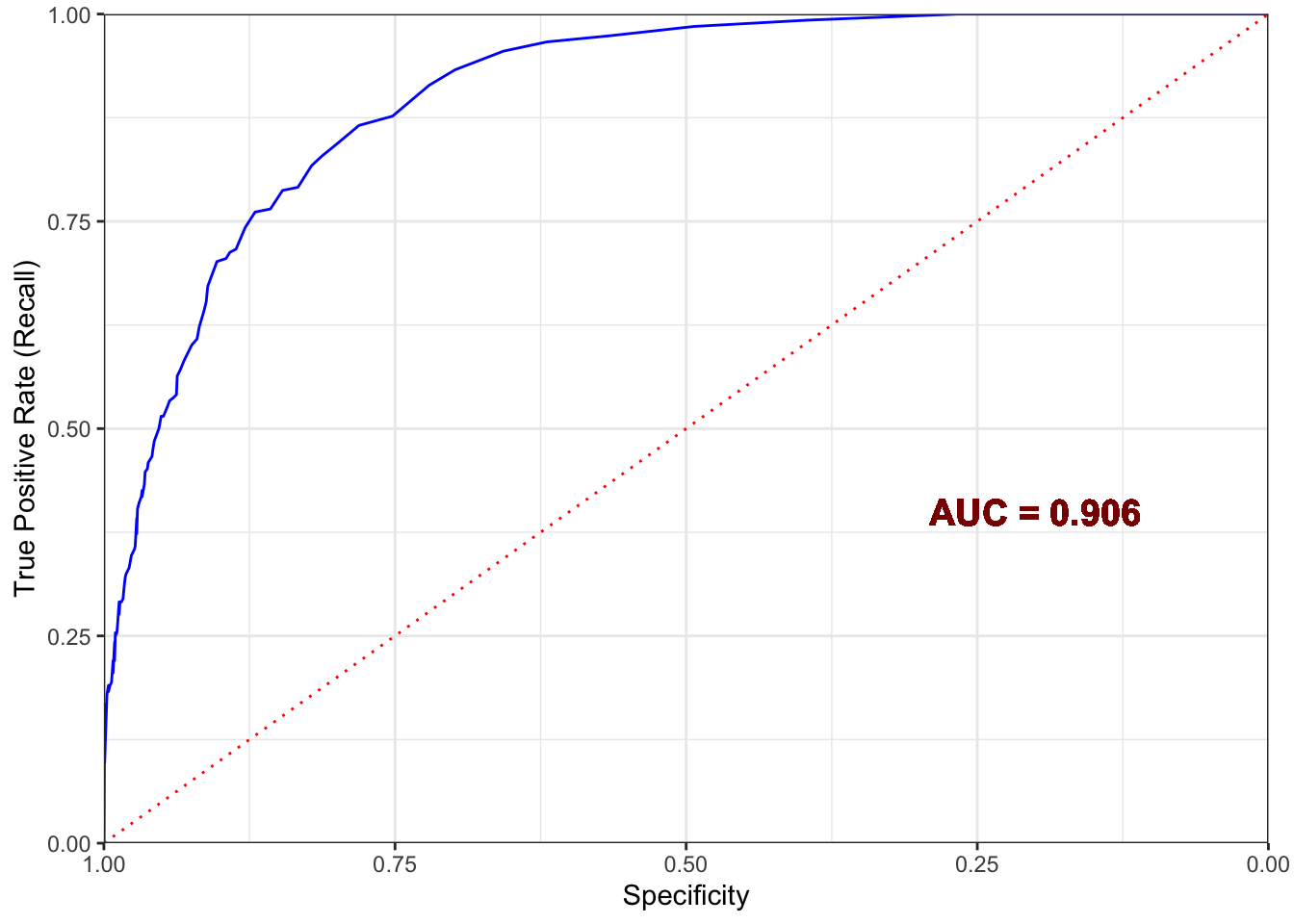
Visualización del ROC y AUC
El AUC es de 0.815 lo que es considerado muy bueno.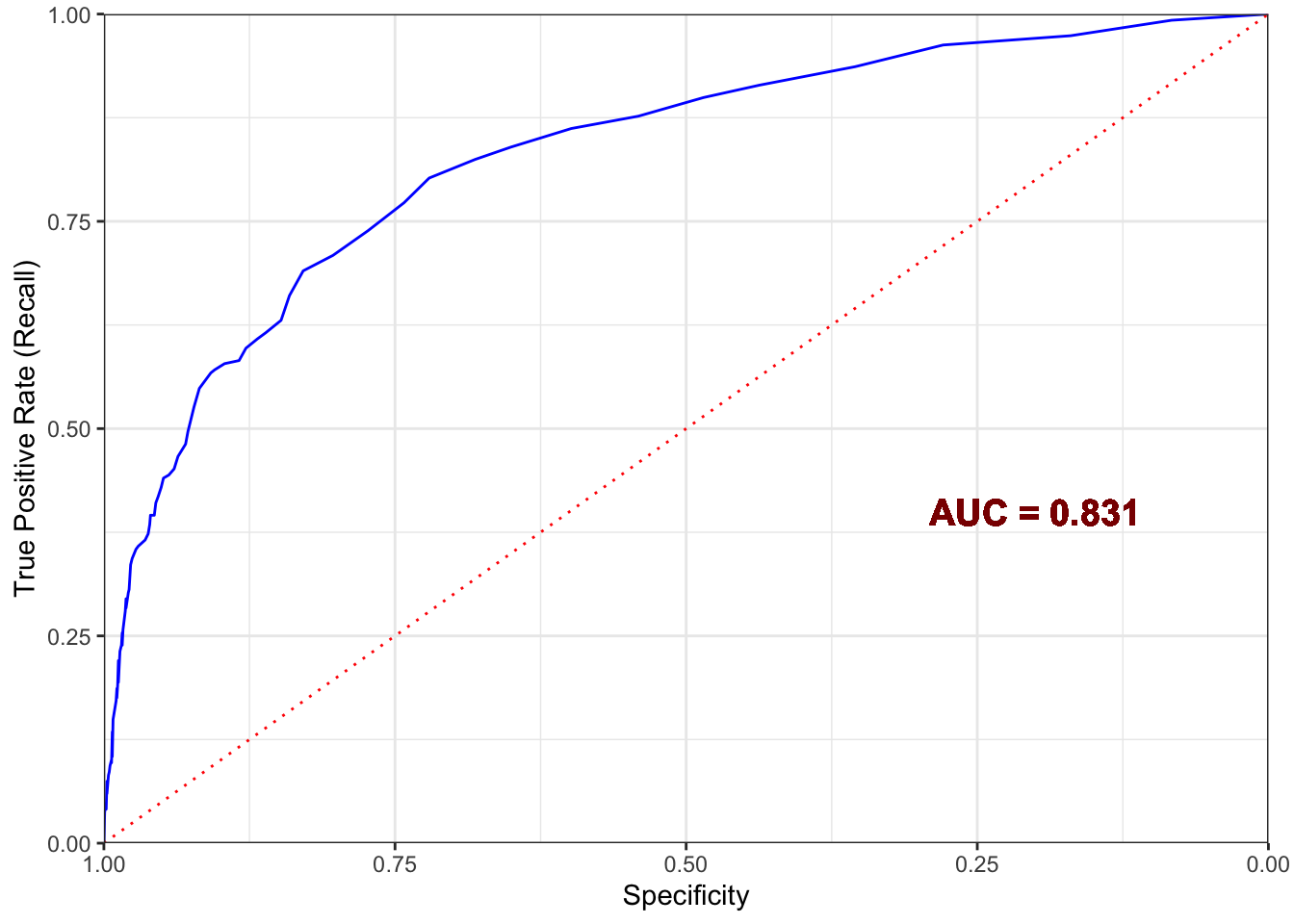
Desempeño fuera de muestra
El modelo demuestra un desempeño aún más satisfactorio en datos no utilizados previamente, lo cual es una señal positiva de su capacidad predictiva.
Sección 5: Mejorando el modelo con Sobremuestreo
Estrategia para datos no balanceados: Sobremuestreo
Ahora utilizaremos la técnica de sobremuestreo para intentar mejorar el modelo.

Desempeño fuera de muestra
La mejora proporcionada por el sobremuestreo no fue lo suficientemente significativa como para justificar su inclusión; por lo tanto, hemos optado por mantener el modelo original sin aplicar la técnica de sobremuestreo.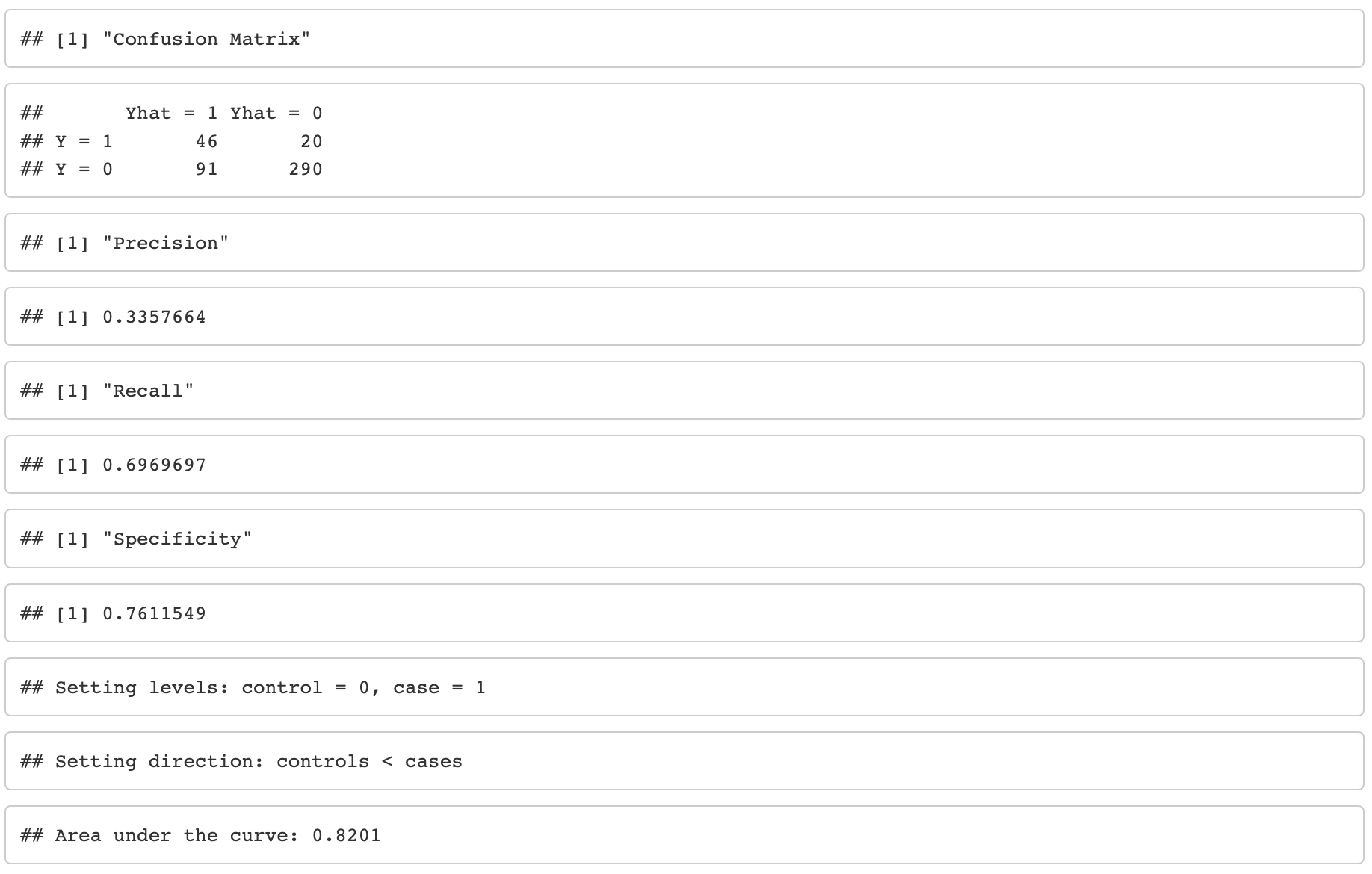
Sección 6: Mejorando el modelo con KNN
K Vecinos más Cercanos.
Primero, intentemos construir un modelo para captar algunas relaciones no lineales que no pudieron ser captadas por el modelo de regresión logística.
Evaluar el modelo de K vecinos más cercanos fuera de muestra

Sin embargo, en la práctica del ajuste del modelo, KNN se puede utilizar para agregar "conocimiento local" en un proceso por etapas con otras técnicas de clasificación. Por lo tanto, agregaremos el resultado de KNN como un nuevo predictor que podría mejorar la capacidad de clasificación en nuestro modelo.
Estableciendo KNN como característica del modelo
Ahora intentemos establecer KNN como una característica y usarlo en el modelo de regresión lineal múltiple para ver si eso podría mejorar el modelo.
Modelo de validación cruzada de 10 pliegues
Evaluando la precisión, exhaustividad y especificidad del modelo


Visualizando la curva ROC y el AUC del modelo
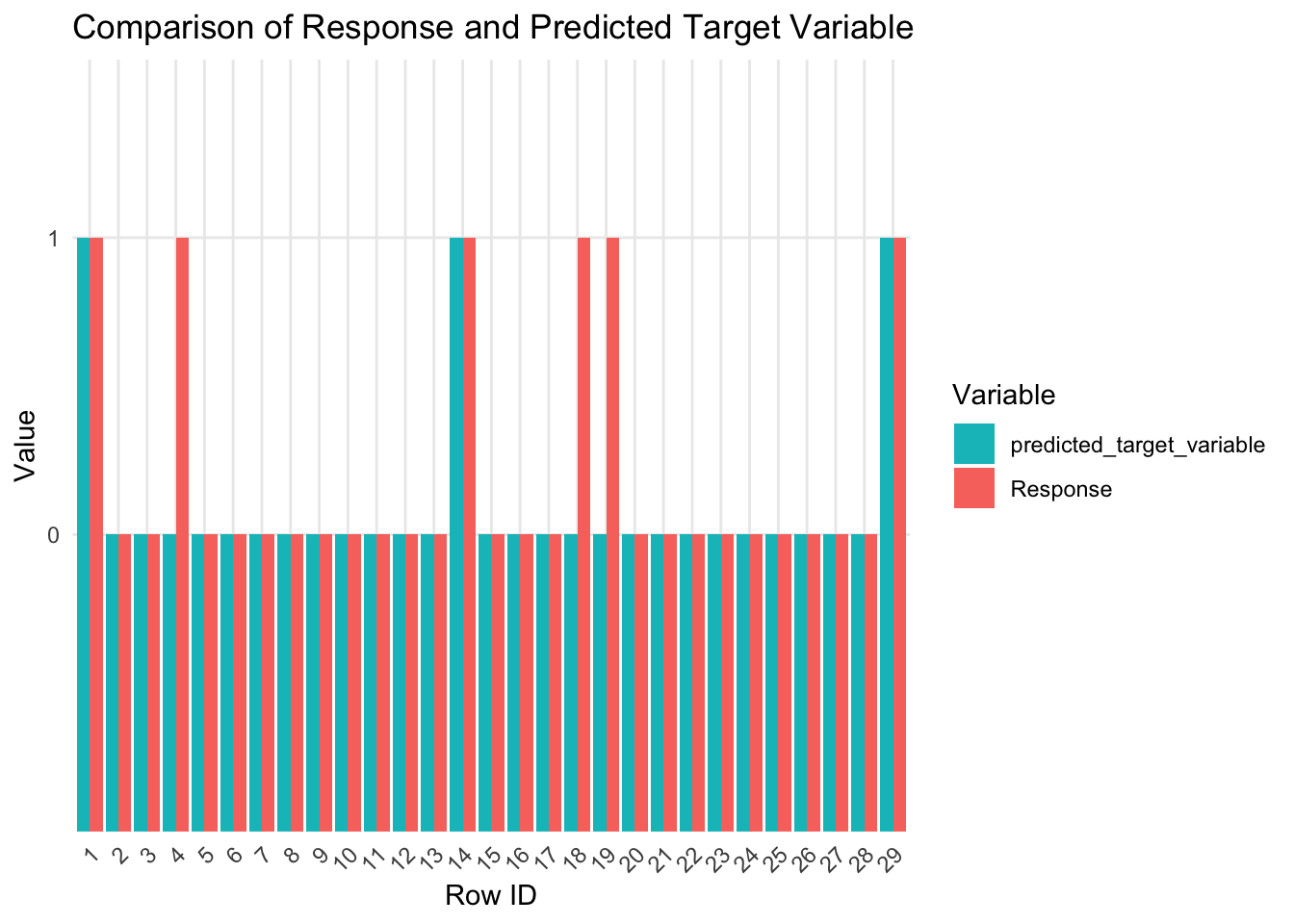
Evaluando el modelo en nuevos datos (fuera de muestra)

Visualizando los valores observados frente a los valores predichos en la muestra de retención
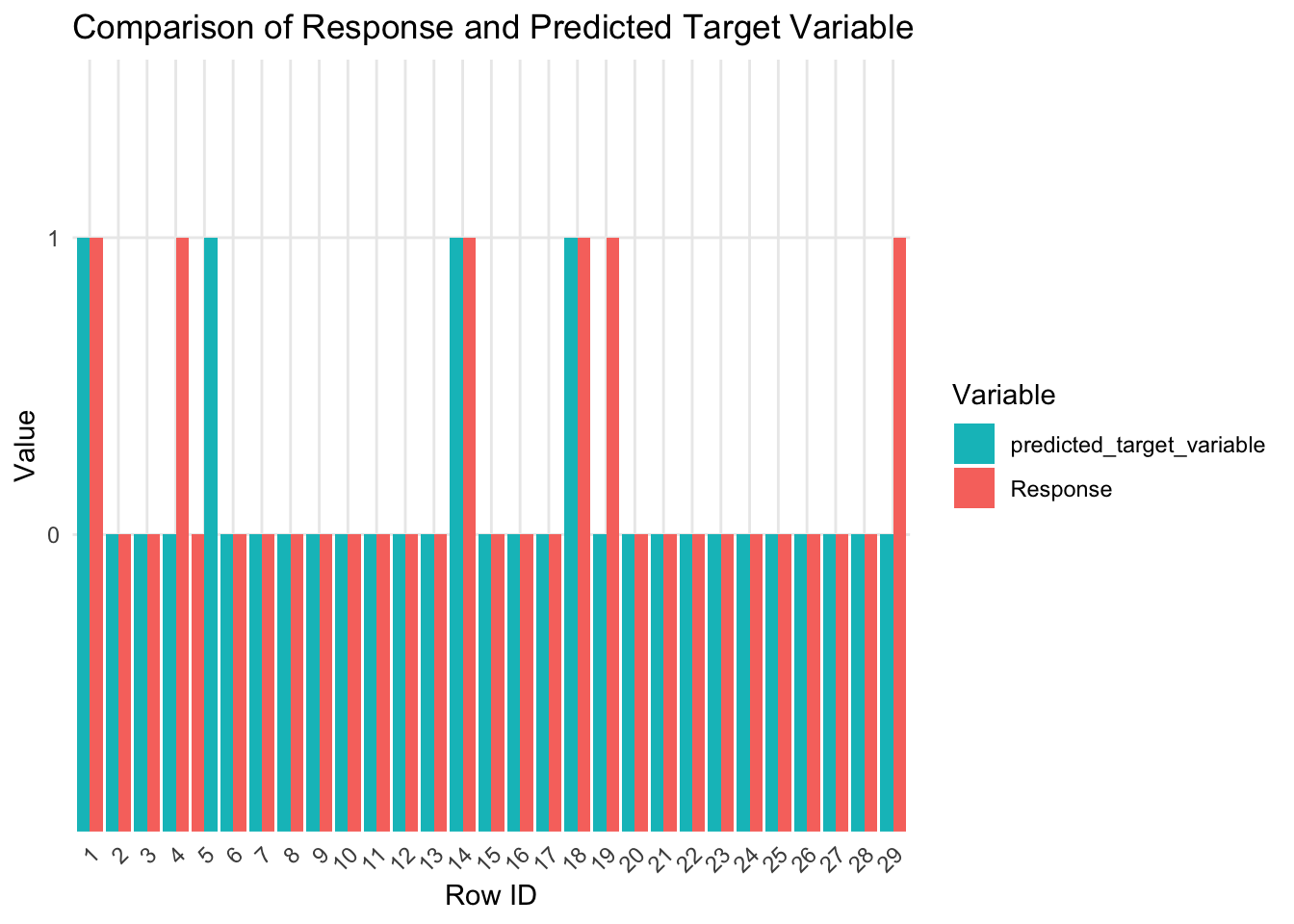
Sección 7: Conclusión
El modelo resultante tiene una precisión del 75%, sensibilidad del 42%, especificidad del 97%, exactitud del 89% y un AUC de 0.831. Este modelo permitirá a la empresa centrar sus campañas de marketing en aquellos clientes que tienen más probabilidades de responder positivamente a la nueva campaña. Al hacerlo, la gestión del presupuesto del departamento se optimizará y las ganancias aumentarán.
La efectividad del modelo podría mejorarse, particularmente en términos de sensibilidad. Sería recomendable explorar otras técnicas de modelado, ajustar parámetros o probar diferentes técnicas de preprocesamiento de datos para mejorar el rendimiento del modelo en esta área.