
Project URL in R:
Clasification-model.notbeook-in-R.html
Tools used:
RStudio, Microsoft Excel, Power Query, Tableau
Section 1: Project Introduction
Problem Description
IFood, a food delivery company that operates through an app, is experiencing stagnant growth and seeks to optimize the performance of its marketing activities, which are currently suffering from poor budget management.
Despite having solid revenues over the past three years, the growth prospects are not promising. Therefore, the company aims to address this issue by focusing on improving the efficiency of its marketing campaigns, particularly the upcoming campaign targeting the sale of a new device to its existing customer base.
Business Objective
"Develop a predictive model based on historical customer data that identifies those most likely to respond positively to the next marketing campaign."
This model should enable the marketing department to make quantitative and informed decisions, resulting in better use of the annual budget and, ultimately, an increase in sales and company growth.
Section 2: Data Description
Features to be provided for model development
For the project, a dataset consisting of records from 2206 customers of XYZ company was provided with information on:
- Customer profiles
- Product preferences
- Campaign successes/failures
- Communication channel performance
| Column | Data type | Sub Data type | Ranges or Categories |
|---|---|---|---|
| 1. ID | Categorical | Nominal | 0-11,191 |
| 2. Age | Numerical | Discrete | 18-21 |
| 3. Income | Numerical | Continuous | 1,730-666,666 |
| 4. Kidhome | Numerical | Discrete | 0-2 |
| 5. Teenhome | Numerical | Discrete | 0-2 |
| 6. Dt_Customer | Numerical | Discrete | 2012-07-30 to 2014-06-29 |
| 7. Recency | Numerical | Discrete | 0-99 |
| 8. MntWines | Numerical | Continuous | 0-1,493 |
| 9. MntFruits | Numerical | Continuous | 0-199 |
| 10. MntMeatProducts | Numerical | Continuous | 0 a 1725 |
| 11. MntFishProducts | Numerical | Continuous | 0-259 |
| 12. MntSweetProducts | Numerical | Continuous | 0-263 |
| 13. MntGoldProds | Numerical | Continuous | 0-362 |
| 14. NumDealsPurchases | Numerical | Discrete | 0 a 15 |
| 15. NumWebPurchases | Numerical | Discrete | 0 a 27 |
| 16. NumCatalogPurchases | Numerical | Discrete | 0 a 28 |
| 17. NumStorePurchases | Numerical | Discrete | 0-13 |
| 18. NumWebVisitsMonth | Numerical | Discrete | 0-20 |
| 19. AcceptedCpm1 | Categorical | Nominal | 0-1 |
| 20. AcceptedCpm2 | Categorical | Nominal | 0-1 |
| 21. AcceptedCpm3 | Categorical | Nominal | 0-1 |
| 22. AcceptedCpm4 | Categorical | Nominal | 0-1 |
| 23. AcceptedCpm5 | Categorical | Nominal | 0-1 |
| 24. Complain | Categorical | Nominal | 0-1 |
| 25. Response | Categorical | Nominal | 0-1 |
| 26. Education | Categorical | Nominal | Graduation, Master, PhD, 2nd Cycle, Basic |
| 27. Marital Status | Categorical | Nominal | Married, Single, Widow, Divorced, Together, Alone, YOLO, Absurd |
Section 3: Findings - Exploratory Data Analysis
Education vs Response
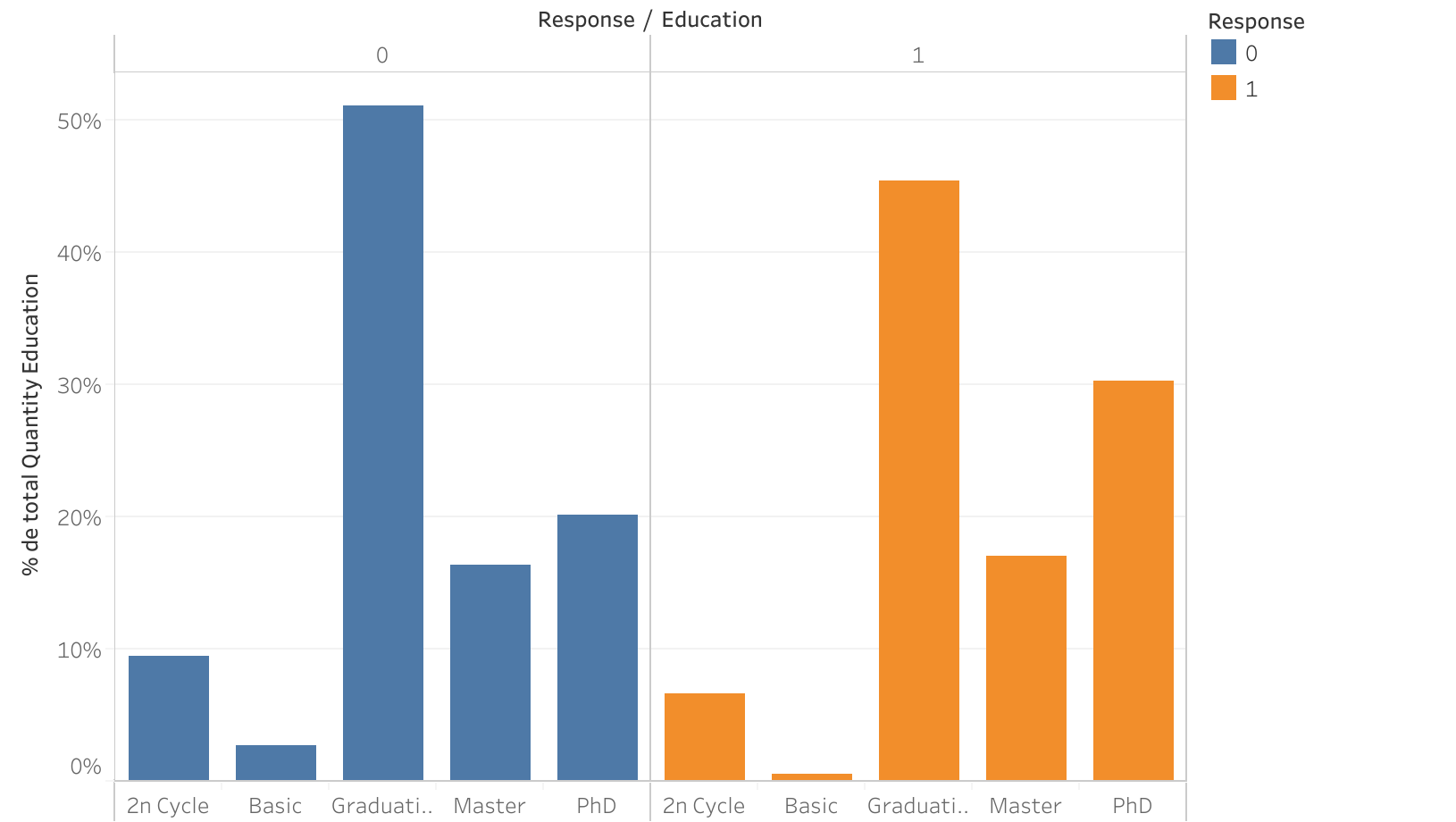
- PhDs showed a higher likelihood of responding positively to the campaign: Of the educational profiles, the one with the most noticeable difference (almost 10%) was PhDs, who responded more positively to the campaign.
Response to previous campaigns vs Response to current campaign
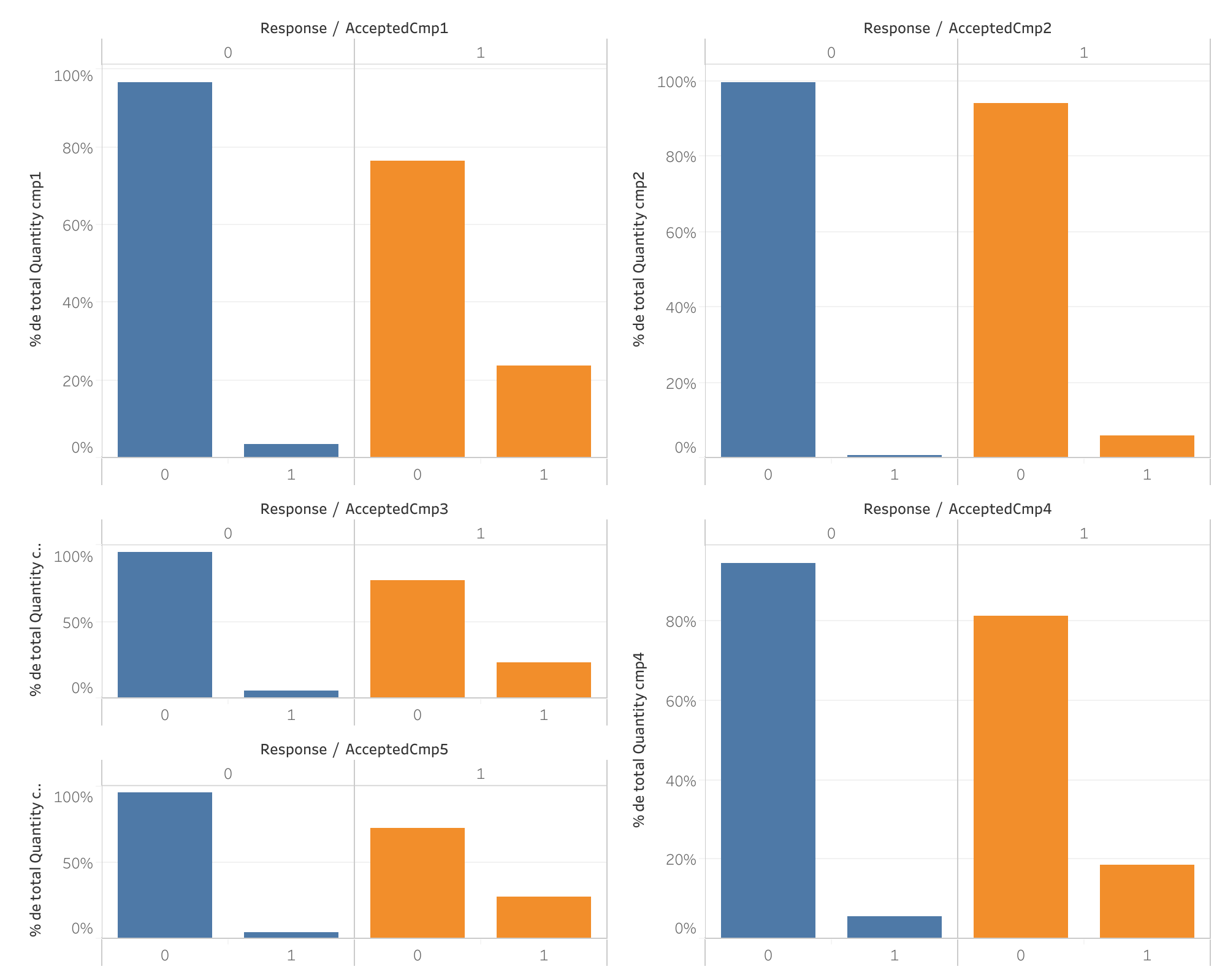
- History repeats itself: Customers who responded positively to previous campaigns showed a higher likelihood of responding positively to the current campaign.
Months of tenure vs Response to current campaign
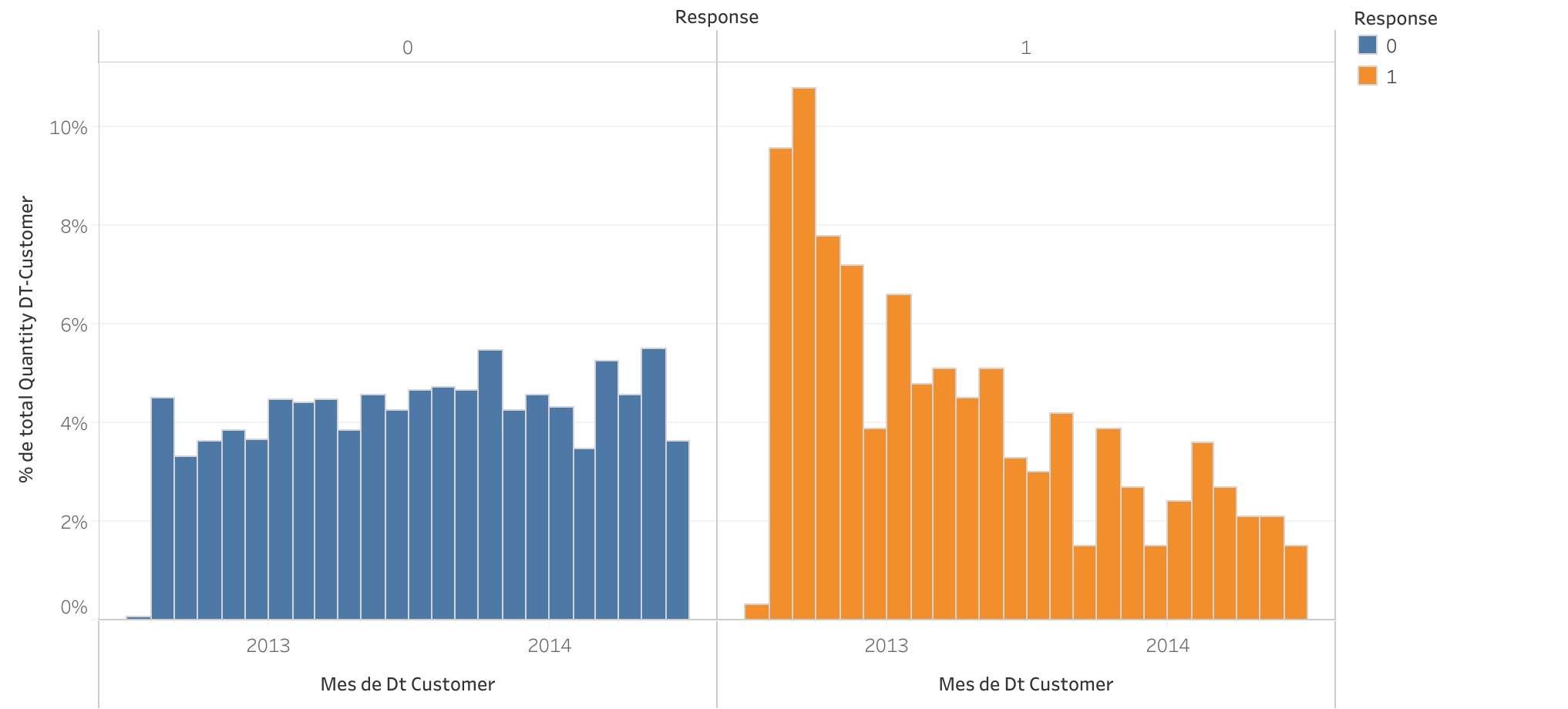
- Longer tenure, better response: Customers with longer tenure since their first use of our services show a higher likelihood of responding positively to the current campaign.
Monthly spending vs Response to current campaign
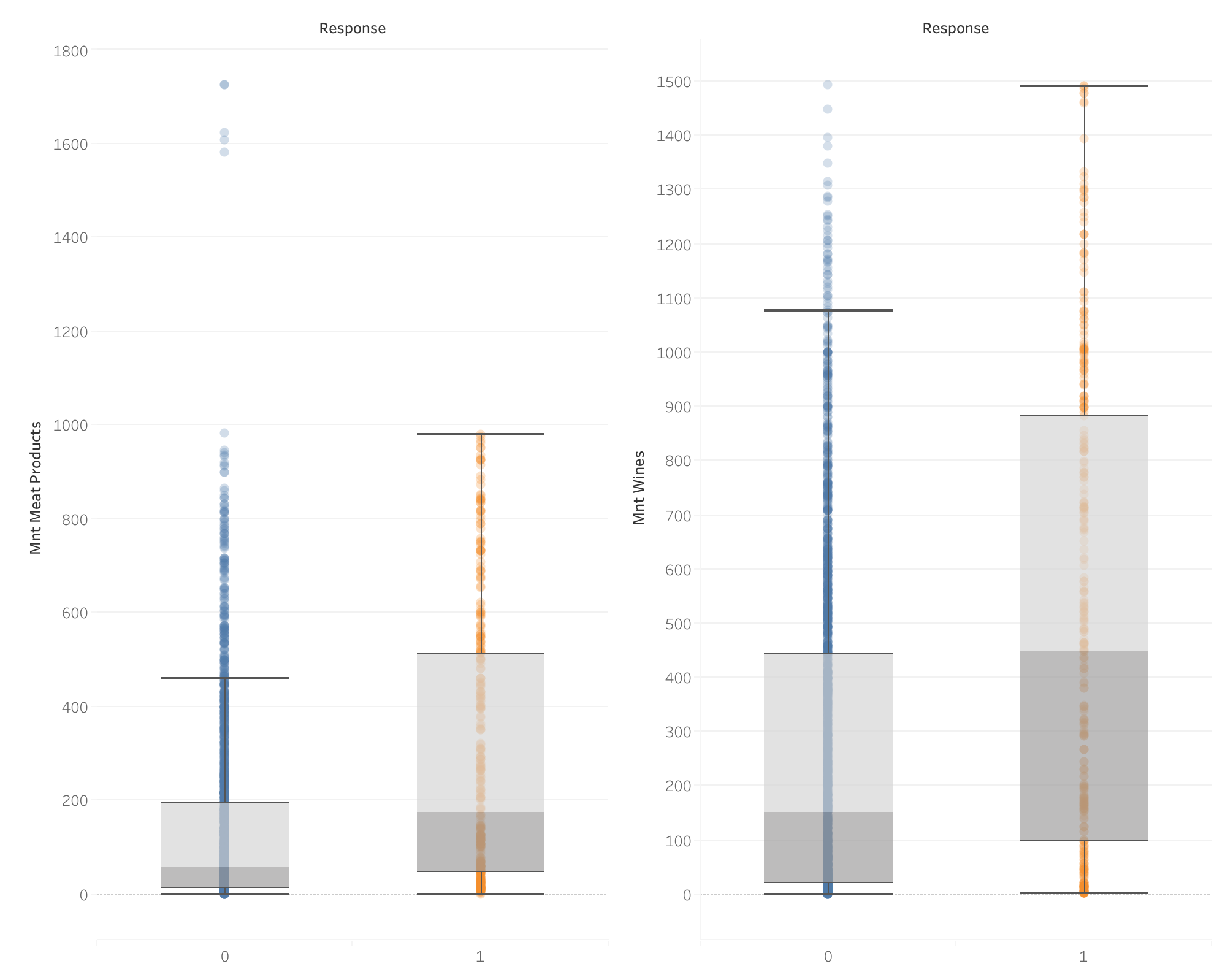
- Bigger spenders have a better response: Customers who spend more, particularly in these two categories (wines and meats), show a higher likelihood of responding positively to the current campaign.
Other attributes vs Response to current campaign
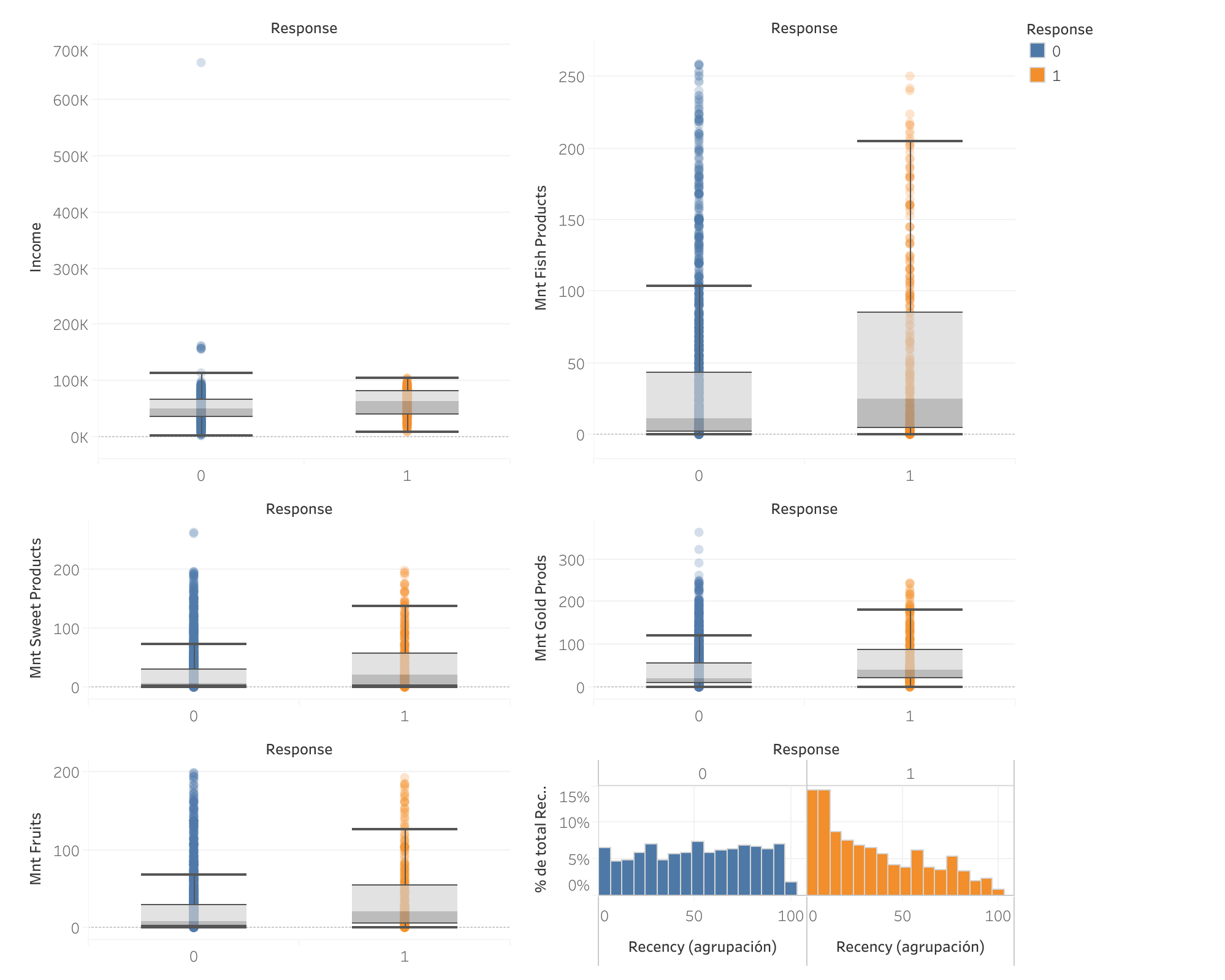
- Interesting differences: Notable differences were identified in various attributes, but none of them were statistically significant or had a considerable impact on the model's predictive ability. Therefore, these attributes were not considered when developing the model.
Section 4: Building the model with Logistic Regression
This section begins after statistical tests and attribute effect analysis, so the attributes to be used by the model have already been selected. If you want to know more about the entire process in detail, visit the project URL at the beginning of this web page.
Logistic Regression
Data split into training and validation sets
An 80%/20% split was chosen.
Multicollinearitys
No multicollinearity was detected in any term (VIF less than 5.0).
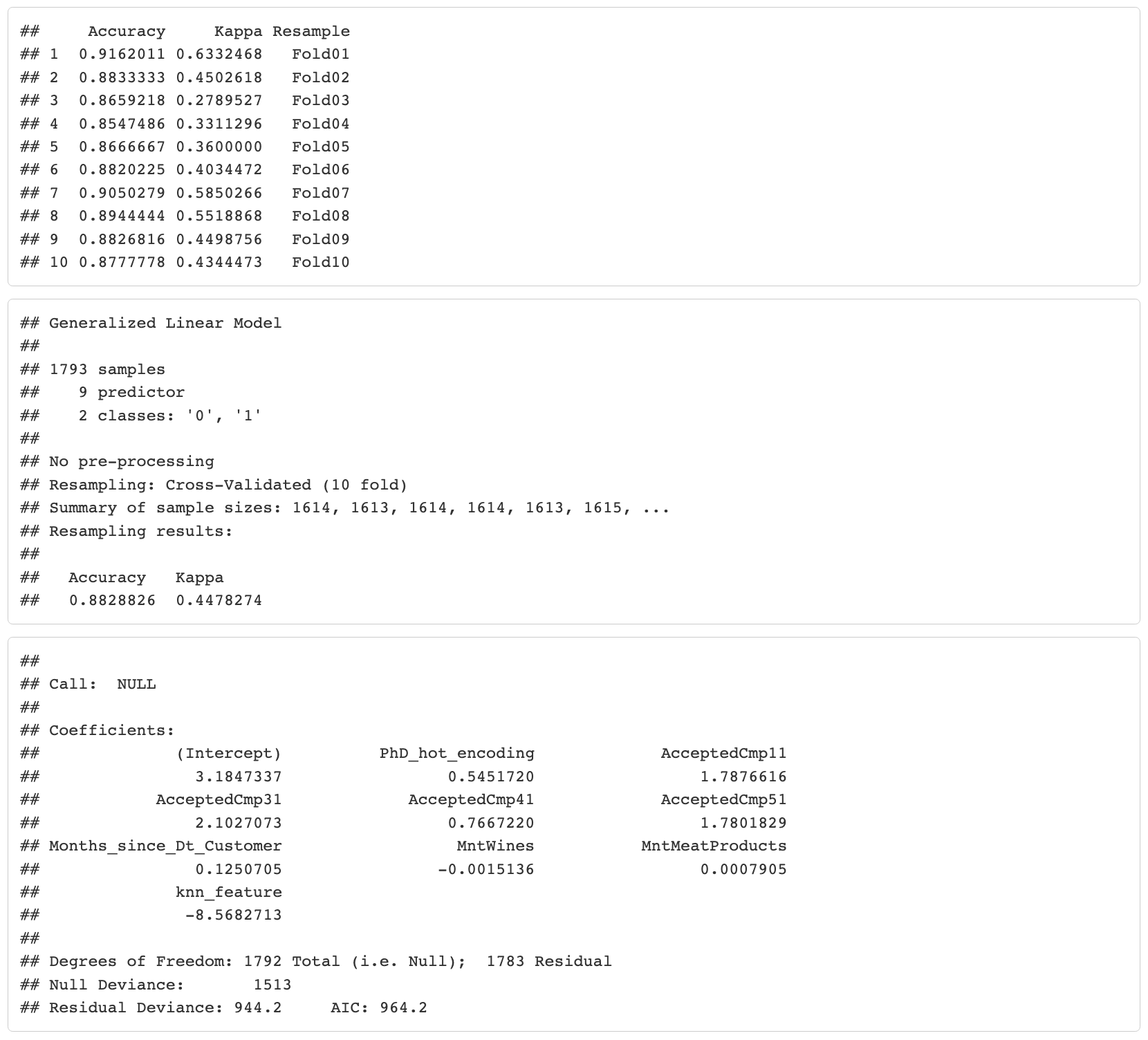
10-fold cross-validation results
The model shows high accuracy (above 85%).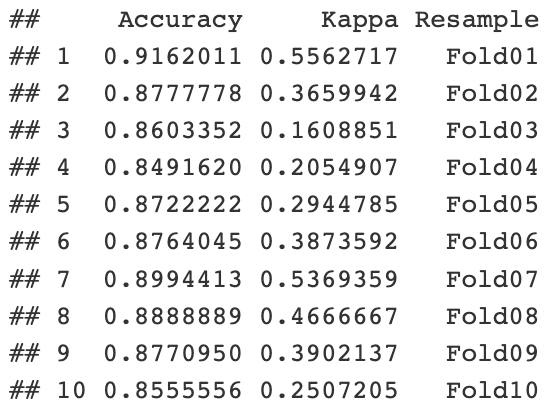

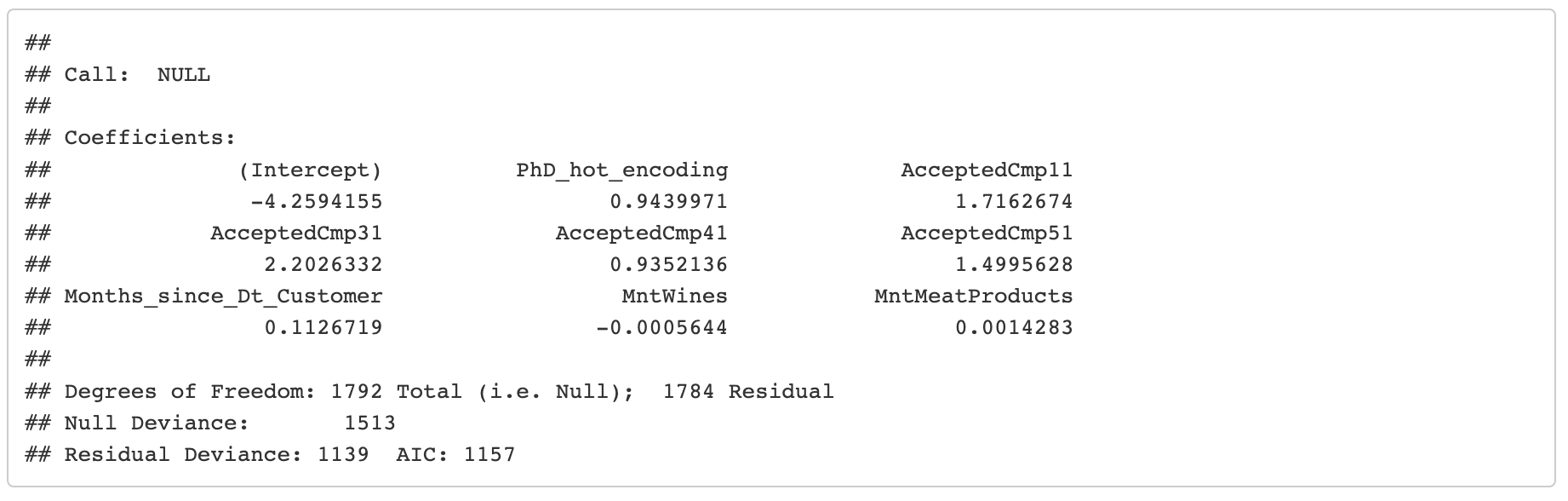
Evaluation of precision, recall, and specificity of the model
The model is good at identifying true positives (71% precision) but lacks sensitivity (30% recall), although sensitivity may not be as important for this project.

ROC and AUC visualization
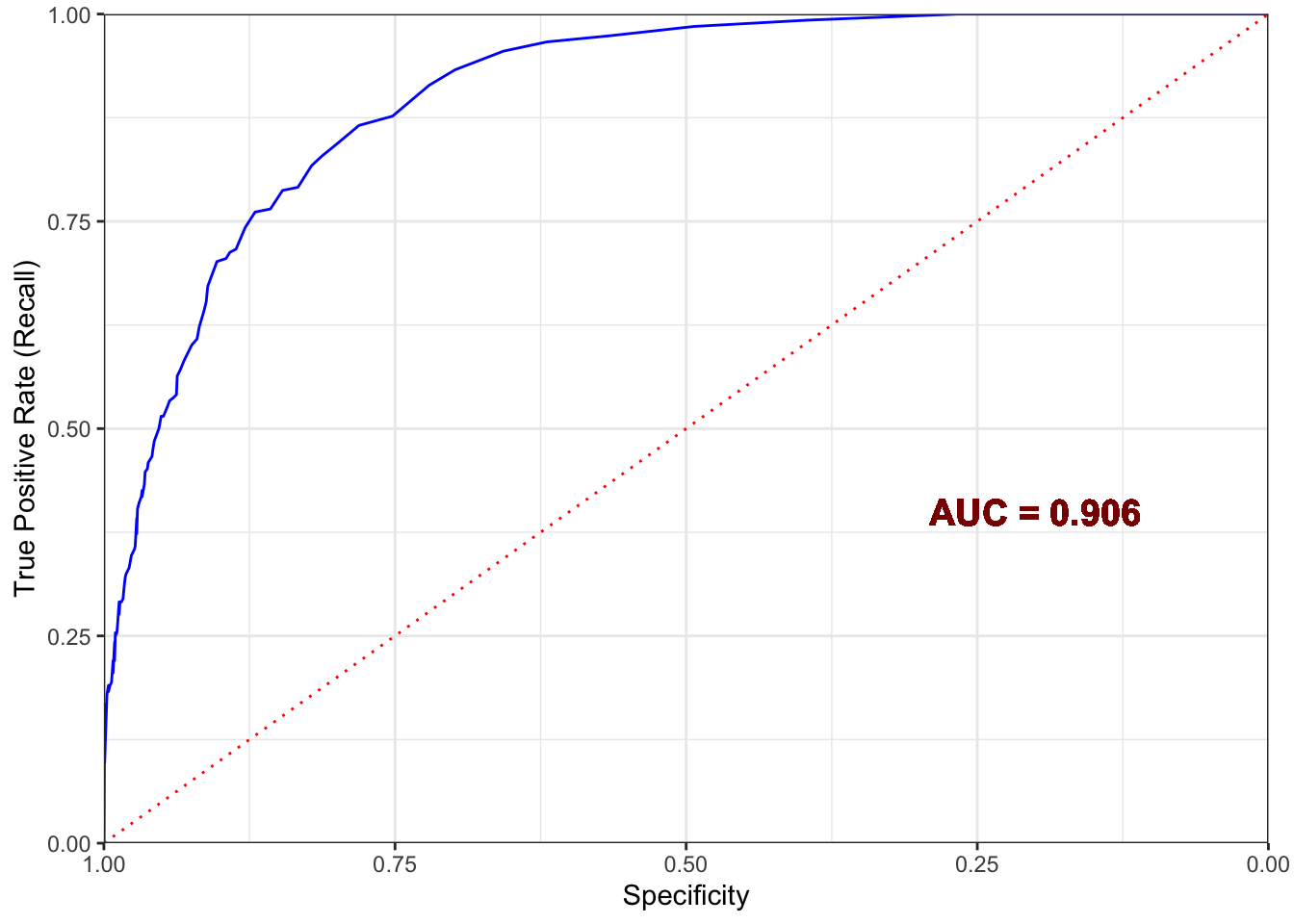
The AUC is 0.815, which is considered very good.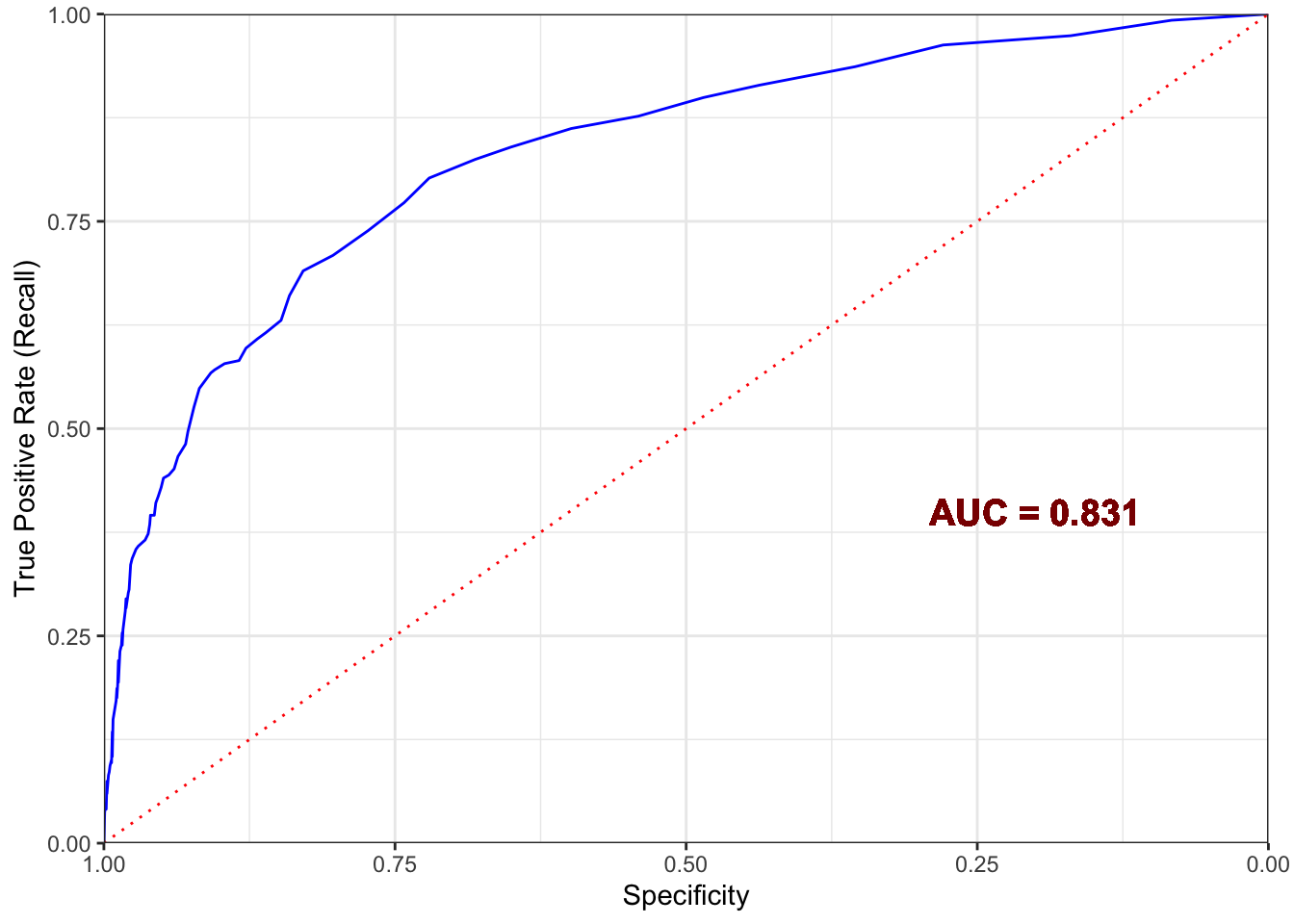
Out-of-sample performance
The model demonstrates even more satisfactory performance on previously unused data, which is a positive sign of its predictive ability.
Section 5: Improving the model with Oversampling
Strategy for imbalanced data: Oversampling
We will now use the oversampling technique to try to improve the model.

Out-of-sample performance
The improvement provided by oversampling was not significant enough to justify its inclusion; therefore, we have chosen to maintain the original model without applying the oversampling technique.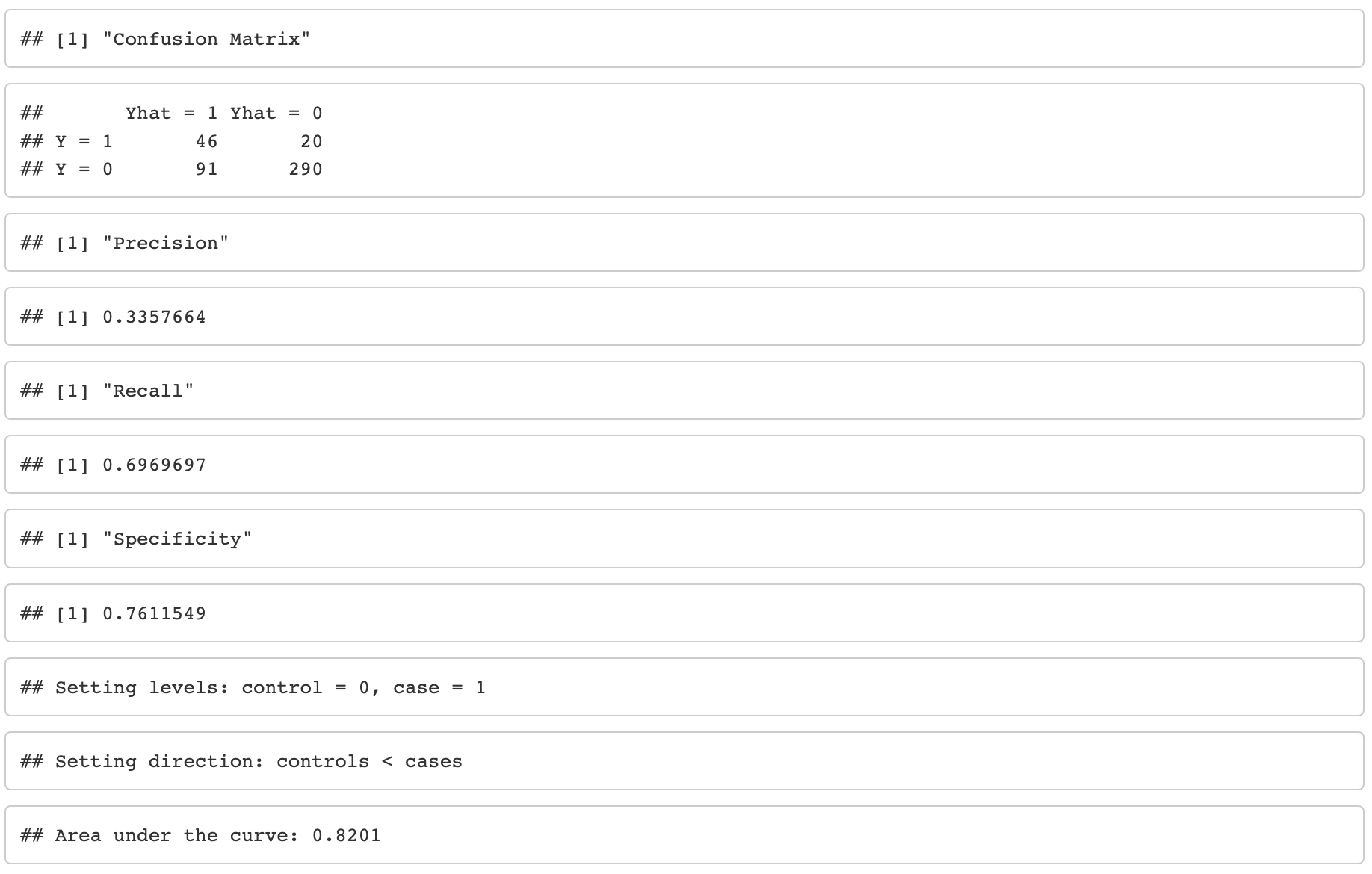
Section 6: Improving the model with KNN
K Nearest Neighbor.
First let’s try to build a model to catch some non-linear relationships that couldn’t be catch by the logistic regression model.
Asses K-nearest neighbors model on Holdout Sample

In practical model fitting, however, KNN can be used to add “local knowledge” in a staged process with other classification techniques Therefore, We’ll add the result of the KNN as a new predictor that could improve the capacity to classify on my model.
Setting KNN as feature engine
Now let’s try setting KNN as a feature and use it in the multiple linear regression model to see if that could improve the model.
10 fold cross validation model
Assessing the model Precision, Recall, and Specificity


Visualizing the model ROC and AUC
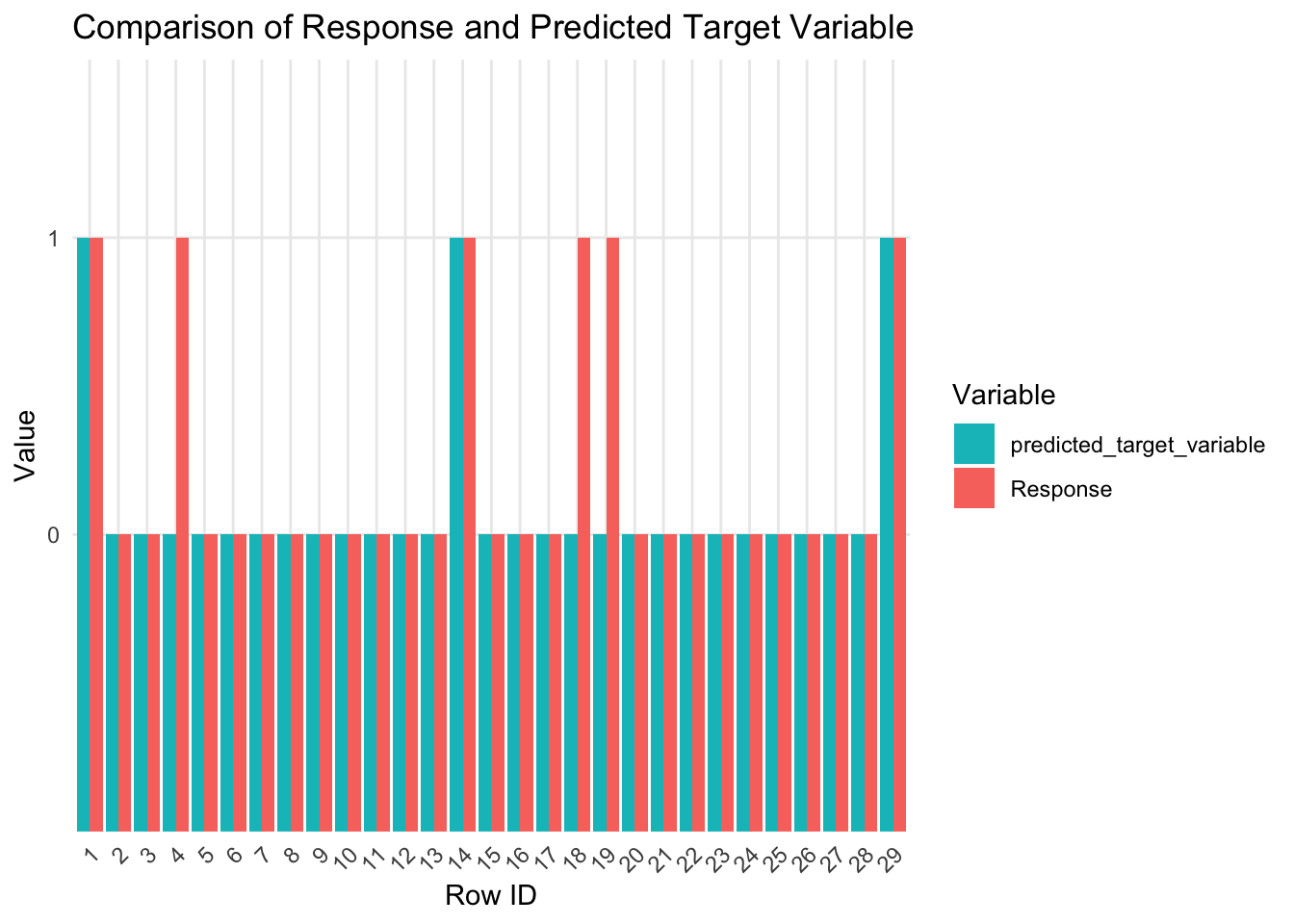
Assessing the model on new data (holdout sample)

Visualizing Observed vs predicted values on holdout sample
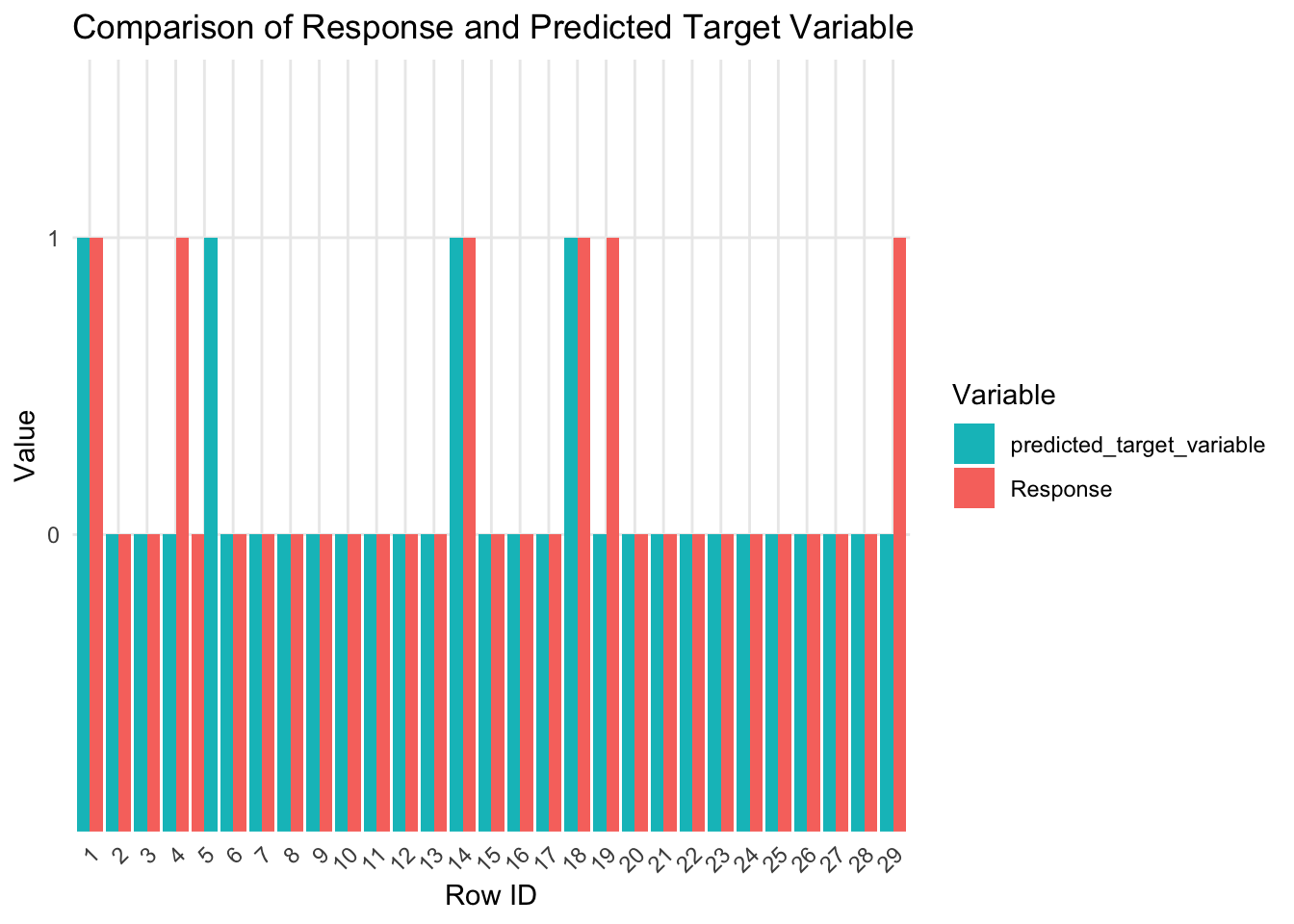
Section 7: Conclusion
The resulting model has a precision of 75%, sensitivity of 42%, specificity of 97%, accuracy of 89%, and an AUC of 0.831. This model will allow the company to focus its marketing campaigns on those customers most likely to respond positively to the new campaign. In doing so, the department's budget management will be optimized, and profits will increase.
The effectiveness of the model could be improved, particularly in terms of sensitivity. It would be advisable to explore other modeling techniques, adjust parameters, or test different data preprocessing techniques to enhance the model's performance in this area.